.NET 6 was released in November 2021, and includes two new types which are of interest to date/time folks: DateOnly and TimeOnly. (Please don’t add comments saying you don’t like the names.) We want to support these types in Noda Time, with conversions between DateOnly and LocalDate, and TimeOnly and LocalTime. To do so, we’ll need a .NET-6-specific target.
Even as a starting point, this is slightly frustrating – we had conditional code differentiating between .NET Framework and PCLs for years, and we finally removed it in 2018. Now we’re having to reintroduce some. Never mind – it can’t be helped, and this is at least simple conditional code.
Targeting .NET 6 requires the .NET 6 SDK of course – upgrading to that was overdue anyway. That wasn’t particularly hard, although it revealed some additional nullable reference type warnings that needed fixing, almost all in tests (or in IComparable.Compare implementations).
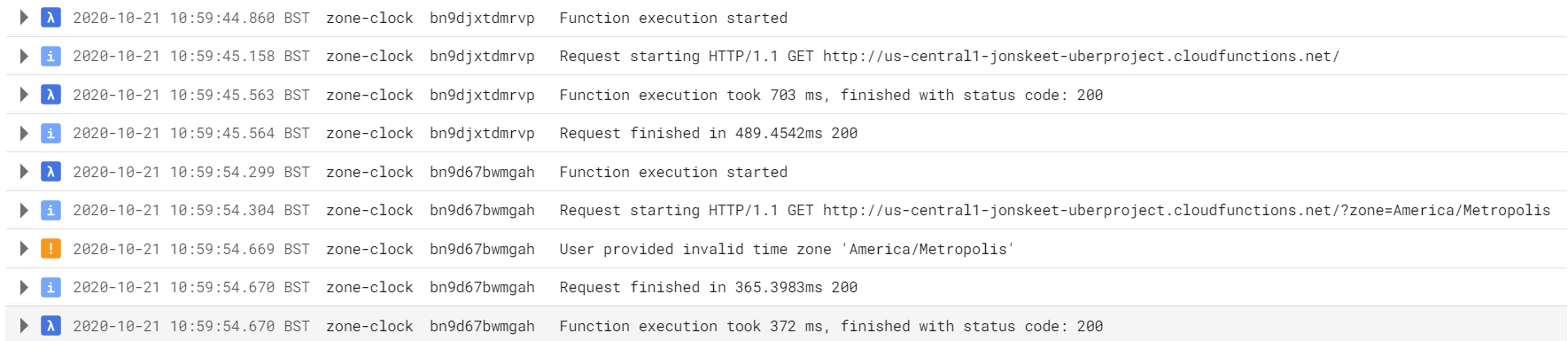
Once everything was working locally, and I’d updated CI to use .NET 6 as well, I figured I’d be ready to start on the DateOnly and TimeOnly support. I was wrong. The pull request intending just to support .NET 6 with absolutely minimal changes failed its unit tests in CI running on Linux. There were 419 failures out of a total of 19334. Ouch! It looked like all of them were in BclDateTimeZoneTest – and fixing those issues is what this post is all about.
Yesterday (at the time of writing – by the time this post is finished it may be in the more distant past) I started trying to look into what was going on. After a little while, I decided that this would be worth blogging about – so most of this post is actually written as I discover more information. (I’m hoping that folks find my diagnostic process interesting, basically.)
Time zones in Noda Time and .NET
Let’s start with a bit of background about how time zones are represented in .NET and Noda Time.
In .NET, time zones are represented by the TimeZoneInfo class (ignoring the legacy TimeZone class). The data used to perform the underlying calculation of “what’s the UTC offset at a given instant in this time zone” are exposed via the GetAdjustmentRules() method, returning an array of the nested TimeZoneInfo.AdjustmentRule class. TimeZoneInfo instances are usually acquired via either TimeZoneInfo.FindSystemTimeZoneById(), TimeZoneInfo.GetSystemTimeZones(), or the TimeZoneInfo.Local static property. On Windows the information is populated from the Windows time zone database (which I believe is in the registry); on Linux it’s populated from files, typically in the /usr/share/zoneinfo directory. For example, the file /usr/share/zoneinfo/Europe/London file contains information about the time zone with the ID “Europe/London”.
In Noda Time, we separate time zones from their providers. There’s an abstract DateTimeZone class, with one public derived class (BclDateTimeZone) and various internal derived classes (FixedDateTimeZone, CachedDateTimeZone, PrecalculatedDateTimeZone) in the main NodaTime package. There are also two public implementations in the NodaTime.Testing package. Most code shouldn’t need to use anything other than DateTimeZone – the only reason BclDateTimeZone is public is to allow users to obtain the original TimeZoneInfo instance that any given BclDateTimeZone was created from.
Separately, there’s an IDateTimeZoneProvider interface. This only has a single implementation normally: DateTimeZoneCache. That cache makes that underlying provider code simpler, as it only has to implement IDateTimeZoneSource (which most users never need to touch). There are two implementations of IDateTimeZoneSource: BclDateTimeZoneSource and TzdbDateTimeZoneSource. The BCL source is for interop with .NET: it uses TimeZoneInfo as a data source, and basically adapts it into a Noda Time representation. The TZDB source implements the IANA time zone database – there’s a “default” set of data built into Noda Time, but you can also load specific data should you need to. (Noda Time uses the term “TZDB” everywhere for historical reasons – when the project started in 2009, IANA wasn’t involved at all. In retrospect, it would have been good to change the name immediately when IANA did get involved in 2011 – that was before the 1.0 release in 2012.)
This post is all about how BclDateTimeZone handles the adjustment rules in TimeZoneInfo. Unfortunately the details of TimeZoneInfo.AdjustmentRule have never been very clearly documented (although it’s better now – see later), and I’ve blogged before about their strange behaviour. The source code for BclDateTimeZone has quite a few comments explaining “unusual” code that basically tries to make up for this. Over the course of writing this post, I’ll be adding some more.
Announced TimeZoneInfo changes in .NET 6
I was already aware that there might be some trouble brewing in .NET 6 when it came to Noda Time, due to enhancements announced when .NET 6 was released. To be clear, I’m not complaining about these enhancements. They’re great for the vast majority of users: you can call TimeZoneInfo.FindSystemTimeZoneById with either an IANA time zone ID (e.g. “Europe/London”) or a Windows time zone ID (e.g. “GMT Standard Time” for the UK, even when it’s not on standard time) and it will return you the “right” time zone, converting the ID if necessary. I already knew I’d need to check what Noda Time was doing and exactly how .NET 6 behaved, to avoid problems.
I suspect that the subject of this post is actually caused by this change though:
Two other minor improvements were made to how adjustment rules are populated from IANA data internally on non-Windows operating systems. They don’t affect external behavior, other than to ensure correctness in some edge cases.
Ensure correctness, eh? They don’t affect external behavior? Hmm. Given what I’ve already seen, I’m pretty sure I’m going to disagree with that assessment. Still, let’s plough on.
Getting started
The test errors in CI (via GitHub actions) seemed to fall into two main buckets, on a very brief inspection:
- Failure to convert a
TimeZoneInfointo aBclDateTimeZoneat all (BclDateTimeZone.FromTimeZoneInfo()throwing an exception) - Incorrect results when using a
BclDateTimeZonethat has been converted. (We validate thatBclDateTimeZonegives the same UTC offsets asTimeZoneInfoaround all the transitions that we’ve detected, and we check once a week for about 100 years as well, just in case we missed any transitions.)
The number of failures didn’t bother me – this is the sort of thing where a one-line change can fix hundreds of tests. But without being confident of where the problem was, I didn’t want to start a “debugging via CI” cycle – that’s just awful.
I do have a machine that can dual boot into Linux, but it’s only accessible when I’m in my shed (as opposed to my living room or kitchen), making it slightly less convenient for debugging than my laptop. But that’s not the only option – there’s WSL 2 which I hadn’t previously looked at. This seemed like the perfect opportunity.
Installing WSL 2 was a breeze, including getting the .NET 6 SDK installed. There’s one choice I’ve made which may or may not be the right one: I’ve cloned the Noda Time repo within Linux, so that when I’m running the tests there it’s as close to being on a “regular” Linux system as normal. I can still use Visual Studio to edit the files (via the WSL mount point of \\wsl.localhost), but it’ll be slightly fiddly to manage. The alternative would be to avoid cloning any of the source code within the Linux file system, instead running the tests from WSL against the source code on the Windows file system. I may change my mind over the best approach half way through…
First, the good news: running the tests against the netcoreapp3.1 target within WSL 2, everything passed first time. Hooray!
Now the bad news: I didn’t get the same errors in WSL 2 that I’d seen in CI. Instead of 419, there were 1688! Yikes. They were still all within BclDateTimeZoneTest though, so I didn’t investigate that discrepancy any further – it may well be a difference in terms of precise SDK versions, or Linux versions. We clearly want everything to work on WSL 2, so let’s get that working first and see what happens in CI. (Part of me does want to understand the differences, to avoid a situation where the tests could pass in CI but not in WSL 2. I may come back to that later, when I understand everything more.)
First issue: abutting maps
The first exception reported in WSL 2 – accounting for the majority of errors – was a conversion failure:
NodaTime.Utility.DebugPreconditionException : Maps must abut (parameter name: maps)
The “map” in question is a PartialZoneIntervalMap, which maps instants to offsets over some interval of time. A time zone (at least for BclDateTimeZone) is created from a sequence of PartialZoneIntervalMaps, where the end of map n is the start of map n+1. The sequence has to cover the whole of time.
As it happens, by the time I’m writing this, I know what the immediate problem is here (because I fixed it last night, before starting to write this blog post) but in the interests of simplicity I’m going to effectively ignore what I did last night, beyond this simplified list:
- I filtered the tests down to a single time zone (to get a smaller log)
- I added more information to the exception (showing the exact start/end that were expected to be the same)
- I added
Console.WriteLinelogging toBclDateTimeZoneconstruction to dump a view of the adjustment rules - I observed and worked around an oddity that we’ll look at shortly
Looking at this now, the fact that it’s a DebugPreconditionException makes me wonder whether this is the difference between CI and local failures: for CI, we run in release mode. Let’s try running the tests in release mode… and yes, we’re down to 419 failures, the same as for CI! That’s encouraging, although it suggests that I might want CI to run tests in debug as well as release mode – at least when the main branch has been updated.
Even before the above list of steps, it seemed likely that the problems would be due changes in the adjustment rule representation in TimeZoneInfo. So at this point, let’s take a steps back and look at what’s meant to be in an adjustment rule, and what we observe in both .NET Core 3.1 and .NET 6.
What’s in an AdjustmentRule?
An adjustment rule covers an interval of time, and describes how the time zone behaves during that interval. (A bit like the PartialZoneIntervalMap mentioned above.)
Let’s start with some good news: it looks like the documentation for TimeZoneInfo.AdjustmentRule has been improved since I last looked at it. It has 6 properties:
BaseUtcOffsetDelta: this is only present in .NET 6, and indicates the difference between “the UTC offset of Standard Time returned byTimeZoneInfo.BaseUtcOffset” and “the UTC offset of Standard Time when this adjustment rule is active”. Effectively this makes up for Windows time zones historically not being able to represent the concept of a zone’s standard time changing.DateStart/DateEnd: the date interval during which the rule applies.DaylightDelta: the delta between standard time and daylight time during this rule. This is typically one hour.DaylightTransitionStart/DaylightTransitionEnd: the information about when the time zone starts and ends daylight saving time (DST) while this rule is in force.
Before we go into the details of DST, there are two “interesting” aspects to DateStart/DateEnd:
Firstly, the documentation doesn’t say whether the rule applies between those UTC dates, or those local dates. I believe they’re local – but that’s an awkard way of specifying things, as local date/time values can be skipped or ambiguous. I really wish this has been set to UTC, and documented as such. Additionally, although you’d expect the transition from one rule to the next to be at midnight (given that only the start/end are only dates), the comments in my existing BclDateTimeZone code suggest that it’s actually at a time of day that depends on the DST transitions times. (It’s very possible that my code is wrong, of course. We’ll look at that in a bit.)
Secondly, the documentation includes this interesting warning (with an example which I’ve snipped out):
Unless there is a compelling reason to do otherwise, you should define the adjustment rule’s start date to occur within the time interval during which the time zone observes standard time. Unless there is a compelling reason to do so, you should not define the adjustment rule’s start date to occur within the time interval during which the time zone observes daylight saving time.
Why? What is likely to go wrong if you violate this? This sort of “here be dragons, but only vaguely specified ones” documentation always feels unhelpful to me. (And yes, I’ve probably written things like that too…)
Anyway, let’s look at the TimeZoneInfo.TransitionTime struct, which is the type of DaylightTransitionStart and DaylightTransitionEnd. The intention is to be able to represent ideas like “3am on February 25th” or “2am on the third Sunday in October”. The first of these is a fixed date rule; the second is a floating date rule (because the day-of-month of “the third Sunday in October” depends on the year). TransitionTime is a struct with 6 properties:
IsFixedDateRule: true for fixed date rules; false for floating date rulesDay(only relevant for fixed date rules): the day-of-month on which the transition occursDayOfWeek(only relevant for floating date rules): the day-of-week on which the transition occursWeek(only relevant for floating date rules): confusingly, this isn’t really “the week of the month” on which the transition occurs; it’s “the occurrence ofDayOfWeekon which the transition occurs”. (The idea of a “Monday to Sunday” or “Sunday to Saturday” week is irrelevant here; it’s just “the first Sunday” or “the second Sunday” etc.) If this has a value of 5, it means “last” regardless of whether that’s the fourth or fifth occurrence.Monththe month of year in which the transition occursTimeOfDay: the local time of day prior to the transition, at which the transition occurs. (So for a transition that skips forward from 1am to 2am for example, this would be 1am. For a transition that skips back from 2am to 1am, this would be 2am.)
Let’s look at the data
From here on, I’m writing and debugging at the same time – any stupid mistakes I make along the way will be documented. (I may go back to indicate that it turned out an idea was stupid at the start of that idea, just to avoid anyone else following it.)
Rather than trying to get bogged down in what the existing Noda Time implementation does, I think it would be useful to compare the data for the same time zone in Windows and Linux, .NET Core 3.1 and .NET 6.
Aha! It looks like I’ve had this idea before! The tool already exists as NodaTime.Tools.DumpTimeZoneInfo. I just need to target it for .NET 6 as well, and add the .NET-6-only BaseUtcOffsetDelta property the completeness.
Interlude: WSL 2 root file issues
Urgh. For some reason, something (I suspect it’s Visual Studio or a background process launched by it, but I’m not sure) keeps on creating files (or modifying existing files) so they’re owned by the root user on the Linux file system. Rather than spending ages investigating this, I’m just going to switch to the alternative mode: use my existing git repo on the Windows file system, and run the code that’s there from WSL when I need to.
(I’m sure this is all configurable and feasible; I just don’t have the energy right now.)
Back to the data…
I’m going to use London as my test time zone, mostly because that’s the time zone I live in, but also because I know it has an interesting oddity between 1968 and 1971, where the UK was on “British Standard Time” – an offset of UTC+1, like “British Summer Time” usually is, but this was “permanent standard time”. In other words, for a few years, our standard UTC offset changed. I’m expecting that to show up in the BaseUtcOffsetDelta property.
So, let’s dump some of the data for the Europe/London time zone, with both .NET Core 3.1 and .NET 6. The full data is very long (due to how the data is represented in the IANA binary format) but here are interesting portions of it, including the start, the British Standard Time experiment, this year (2022) and the last few lines:
.NET Core 3.1:
Zone ID: Europe/London Display name: (UTC+00:00) GMT Standard name: GMT Daylight name: GMT+01:00 Base offset: 00:00:00 Supports DST: True Rules: 0001-01-01 - 1847-12-01: Daylight delta: +00; DST starts January 01 at 00:00:00 and ends December 01 at 00:01:14 1847-12-01 - 1916-05-21: Daylight delta: +00; DST starts December 01 at 00:01:15 and ends May 21 at 01:59:59 1916-05-21 - 1916-10-01: Daylight delta: +01; DST starts May 21 at 02:00:00 and ends October 01 at 02:59:59 1916-10-01 - 1917-04-08: Daylight delta: +00; DST starts October 01 at 02:00:00 and ends April 08 at 01:59:59 ... 1967-03-19 - 1967-10-29: Daylight delta: +01; DST starts March 19 at 02:00:00 and ends October 29 at 02:59:59 1967-10-29 - 1968-02-18: Daylight delta: +00; DST starts October 29 at 02:00:00 and ends February 18 at 01:59:59 1968-02-18 - 1968-10-26: Daylight delta: +01; DST starts February 18 at 02:00:00 and ends October 26 at 23:59:59 1968-10-26 - 1971-10-31: Daylight delta: +00; DST starts October 26 at 23:00:00 and ends October 31 at 01:59:59 1971-10-31 - 1972-03-19: Daylight delta: +00; DST starts October 31 at 02:00:00 and ends March 19 at 01:59:59 1972-03-19 - 1972-10-29: Daylight delta: +01; DST starts March 19 at 02:00:00 and ends October 29 at 02:59:59 1972-10-29 - 1973-03-18: Daylight delta: +00; DST starts October 29 at 02:00:00 and ends March 18 at 01:59:59 ... 2022-03-27 - 2022-10-30: Daylight delta: +01; DST starts March 27 at 01:00:00 and ends October 30 at 01:59:59 2022-10-30 - 2023-03-26: Daylight delta: +00; DST starts October 30 at 01:00:00 and ends March 26 at 00:59:59 ... 2036-03-30 - 2036-10-26: Daylight delta: +01; DST starts March 30 at 01:00:00 and ends October 26 at 01:59:59 2036-10-26 - 2037-03-29: Daylight delta: +00; DST starts October 26 at 01:00:00 and ends March 29 at 00:59:59 2037-03-29 - 2037-10-25: Daylight delta: +01; DST starts March 29 at 01:00:00 and ends October 25 at 01:59:59 2037-10-25 - 9999-12-31: Daylight delta: +01; DST starts October 25 at 01:00:00 and ends December 31 at 23:59:59
.NET 6:
Zone ID: Europe/London Display name: (UTC+00:00) United Kingdom Time Standard name: Greenwich Mean Time Daylight name: British Summer Time Base offset: 00:00:00 Supports DST: True Rules: 0001-01-01 - 0001-12-31: Base UTC offset delta: -00:01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends December 31 at 23:59:59.999 0002-01-01 - 1846-12-31: Base UTC offset delta: -00:01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends December 31 at 23:59:59.999 1847-01-01 - 1847-12-01: Base UTC offset delta: -00:01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends December 01 at 00:01:14.999 1916-05-21 - 1916-10-01: Daylight delta: +01; DST starts May 21 at 02:00:00 and ends October 01 at 02:59:59.999 1917-04-08 - 1917-09-17: Daylight delta: +01; DST starts April 08 at 02:00:00 and ends September 17 at 02:59:59.999 1918-03-24 - 1918-09-30: Daylight delta: +01; DST starts March 24 at 02:00:00 and ends September 30 at 02:59:59.999 ... 1967-03-19 - 1967-10-29: Daylight delta: +01; DST starts March 19 at 02:00:00 and ends October 29 at 02:59:59.999 1968-02-18 - 1968-10-26: Daylight delta: +01; DST starts February 18 at 02:00:00 and ends October 26 at 23:59:59.999 1968-10-26 - 1968-12-31: Base UTC offset delta: +01; Daylight delta: +00; DST starts October 26 at 23:00:00 and ends December 31 at 23:59:59.999 1969-01-01 - 1970-12-31: Base UTC offset delta: +01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends December 31 at 23:59:59.999 1971-01-01 - 1971-10-31: Base UTC offset delta: +01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends October 31 at 01:59:59.999 1972-03-19 - 1972-10-29: Daylight delta: +01; DST starts March 19 at 02:00:00 and ends October 29 at 02:59:59.999 1973-03-18 - 1973-10-28: Daylight delta: +01; DST starts March 18 at 02:00:00 and ends October 28 at 02:59:59.999 ... 2022-03-27 - 2022-10-30: Daylight delta: +01; DST starts March 27 at 01:00:00 and ends October 30 at 01:59:59.999 ... 2037-03-29 - 2037-10-25: Daylight delta: +01; DST starts March 29 at 01:00:00 and ends October 25 at 01:59:59.999 2037-10-25 - 9999-12-31: Daylight delta: +01; DST starts Last Sunday of March; 01:00:00 and ends Last Sunday of October; 02:00:00
Wow… that’s quite a difference. Let’s see:
- The names (display/standard/daylight) are all different – definitely better in .NET 6.
- .NET 6 appears to have one rule for the year 1, and then another (but identical) for years 2 to 1846
- .NET 6 doesn’t have any rules between 1847 and 1916
- .NET 6 only uses one rule per year, starting and ending at the DST boundaries; .NET Core 3.1 had one rule for each transition
- The .NET Core 3.1 rules end at 59 minutes past the hour (e.g. 01:59:59) whereas the .NET 6 rules finish 999 milliseconds later
Fixing the code
So my task is to “interpret” all of this rule data in Noda Time, bearing in mind that:
- It needs to work with Windows data as well (which has its own quirks)
- It probably shouldn’t change logic based on which target framework it was built against, as I suspect it’s entirely possible
for the DLL targeting .NET Standard 2.0 to end up running in .NET 6.
We do already have code that behaves differently based on whether it believes
the rule data comes from Windows or Unix – Windows rules always start on January 1st and end on December 31st, so if all
the rules in a zone follow that pattern, we assume we’re dealing with Windows data. That makes it slightly easier.
Likewise, we already have code that assumes any gaps between rules are in standard time – so actually the fact that .NET 6 only reports half as many rules probably won’t cause a problem.
Let’s start by handling the difference of transitions finishing at x:59:59 vs x:59:59.999. The existing code always adds 1 second to the end time, to account for x:59:59. It’s easy enough to adjust that to add either 1 second or 1 millisecond. This error was what caused our maps to have problems, I suspect. (We’d have a very weird situation in a few cases where one map started after the previous one ended.)
// This is added to the declared end time, so that it becomes an exclusive upper bound. var endTimeCompensation = Duration.FromSeconds(1) - Duration.FromMilliseconds(bclLocalEnd.Millisecond);
Let’s try it: dotnet test -f net6.0
Good grief. Everything passed. Better try it with 3.1 as well: dotnet test -f netcoreapp3.1
Yup, everything passed there, too. And on Windows, although that didn’t surprise me much, given that we have separate paths.
This surprises me for two reasons:
- Last night, when just experimenting, I made a change to just subtract
bclLocalEnd.Millisecondmilliseconds frombclLocalEnd(i.e. truncate it down). That helped a lot, but didn’t fix everything. - The data has changed really quite substantially, so I’m surprised that there aren’t extra issues. Do we get the “standard offset” correct during the British Standard Time experiment, for example?
I’m somewhat suspicious of the first bullet point… so I’m going to stash the fix, and try to reproduce last night.
Testing an earlier partial fix (or not…)
First, I remember that I did something I definitely wanted to keep last night. When adjacent maps don’t abut, let’s throw a better exception.
So before I do anything else, let’s reproduce the original errors: dotnet test -f net6.0
Ah. It still passes. Doh! When I thought I was running the .NET 6 tests under Linux, it turned out I was still in a Windows tab in Windows Terminal. (I use bash in all my terminals, so there’s not quite as much distinction as you might expect.) Well, that at least explains why the small fix worked rather better than expected. Sigh.
Okay, let’s rerun the tests… and they fail as expected. Now let’s add more details to the exception before reapplying the fix… done.
The resulting exception is clearer, and makes it obvious that the error is due to the 999ms discrepancy:
NodaTime.Utility.DebugPreconditionException : Maps must abut: 0002-01-01T00:00:00.999 != 0002-01-01T00:00:00
Let’s reapply the fix from earlier, which we expect to solve that problem but not everything. Retest… and we’re down to 109 failures rather than 1688. Much better, but not great.
Let’s understand one new error
We’re still getting errors of non-abutting maps, but now they’re (mostly) an hour out, rather than 999ms. Here’s one from Europe/Prague:
NodaTime.Utility.DebugPreconditionException : Maps must abut: 1947-01-01T00:00:00 != 1946-12-31T23:00:00
Most errors are in the 20th century, although there are some in 2038 and 2088, which is odd. Let’s have a look at the raw data for Prague around the time that’s causing problems, and we can see whether fixing just Prague helps with anything else.
.NET 6 data:
1944-04-03 - 1944-10-02: Daylight delta: +01; DST starts April 03 at 02:00:00 and ends October 02 at 02:59:59.999 1945-04-02 - 1945-05-08: Daylight delta: +01; DST starts April 02 at 02:00:00 and ends May 08 at 23:59:59.999 1945-05-08 - 1945-10-01: Daylight delta: +01; DST starts May 08 at 23:00:00 and ends October 01 at 02:59:59.999 1946-05-06 - 1946-10-06: Daylight delta: +01; DST starts May 06 at 02:00:00 and ends October 06 at 02:59:59.999 1946-12-01 - 1946-12-31: Daylight delta: -01; DST starts December 01 at 03:00:00 and ends December 31 at 23:59:59.999 1947-01-01 - 1947-02-23: Daylight delta: -01; DST starts January 01 at 00:00:00 and ends February 23 at 01:59:59.999 1947-04-20 - 1947-10-05: Daylight delta: +01; DST starts April 20 at 02:00:00 and ends October 05 at 02:59:59.999 1948-04-18 - 1948-10-03: Daylight delta: +01; DST starts April 18 at 02:00:00 and ends October 03 at 02:59:59.999 1949-04-09 - 1949-10-02: Daylight delta: +01; DST starts April 09 at 02:00:00 and ends October 02 at 02:59:59.999 1979-04-01 - 1979-09-30: Daylight delta: +01; DST starts April 01 at 02:00:00 and ends September 30 at 02:59:59.999
This is interesting – most years have just one rule, but the three years of 1945-1947 have two rules each.
Let’s look at the .NET Core 3.1 representation – which comes from the same underlying file, as far as I’m aware:
1944-10-02 - 1945-04-02: Daylight delta: +00; DST starts October 02 at 02:00:00 and ends April 02 at 01:59:59 1945-04-02 - 1945-05-08: Daylight delta: +01; DST starts April 02 at 02:00:00 and ends May 08 at 23:59:59 1945-05-08 - 1945-10-01: Daylight delta: +01; DST starts May 08 at 23:00:00 and ends October 01 at 02:59:59 1945-10-01 - 1946-05-06: Daylight delta: +00; DST starts October 01 at 02:00:00 and ends May 06 at 01:59:59 1946-05-06 - 1946-10-06: Daylight delta: +01; DST starts May 06 at 02:00:00 and ends October 06 at 02:59:59 1946-10-06 - 1946-12-01: Daylight delta: +00; DST starts October 06 at 02:00:00 and ends December 01 at 02:59:59 1946-12-01 - 1947-02-23: Daylight delta: -01; DST starts December 01 at 03:00:00 and ends February 23 at 01:59:59 1947-02-23 - 1947-04-20: Daylight delta: +00; DST starts February 23 at 03:00:00 and ends April 20 at 01:59:59 1947-04-20 - 1947-10-05: Daylight delta: +01; DST starts April 20 at 02:00:00 and ends October 05 at 02:59:59 1947-10-05 - 1948-04-18: Daylight delta: +00; DST starts October 05 at 02:00:00 and ends April 18 at 01:59:59 1948-04-18 - 1948-10-03: Daylight delta: +01; DST starts April 18 at 02:00:00 and ends October 03 at 02:59:59 1948-10-03 - 1949-04-09: Daylight delta: +00; DST starts October 03 at 02:00:00 and ends April 09 at 01:59:59 1949-04-09 - 1949-10-02: Daylight delta: +01; DST starts April 09 at 02:00:00 and ends October 02 at 02:59:59 1949-10-02 - 1978-12-31: Daylight delta: +00; DST starts October 02 at 02:00:00 and ends December 31 at 23:59:59 1979-01-01 - 1979-04-01: Daylight delta: +00; DST starts January 01 at 00:00:00 and ends April 01 at 01:59:59
Okay, so that makes a certain amount of sense – it definitely shows that there was something unusual happening in the Europe/Prague time zone. Just as one extra point of data, let’s look at the nodatime.org tzvalidate results – this shows all transitions. (tzvalidate is a format designed to allow authors of time zone library code to validate that they’re interpreting the IANA data the same way as each other.)
Europe/Prague Initially: +01:00:00 standard CET 1944-04-03 01:00:00Z +02:00:00 daylight CEST 1944-10-02 01:00:00Z +01:00:00 standard CET 1945-04-02 01:00:00Z +02:00:00 daylight CEST 1945-10-01 01:00:00Z +01:00:00 standard CET 1946-05-06 01:00:00Z +02:00:00 daylight CEST 1946-10-06 01:00:00Z +01:00:00 standard CET 1946-12-01 02:00:00Z +00:00:00 daylight GMT 1947-02-23 02:00:00Z +01:00:00 standard CET 1947-04-20 01:00:00Z +02:00:00 daylight CEST 1947-10-05 01:00:00Z +01:00:00 standard CET 1948-04-18 01:00:00Z +02:00:00 daylight CEST 1948-10-03 01:00:00Z +01:00:00 standard CET 1949-04-09 01:00:00Z +02:00:00 daylight CEST 1949-10-02 01:00:00Z +01:00:00 standard CET
Again there’s that odd period from December 1946 to near the end of February 1947 where there’s daylight savings of -1 hour. I’m not interested in the history of that right now – I’m interested in why the code is failing.
In this particular case, it looks like the problem is we’ve got two adjacent rules in .NET 6 (one at the end of 1946 and the other at the start of 1947) which both just describe periods of daylight saving.
If we can construct the maps to give the right results, Noda Time already has code in to work out “that’s okay, there’s no transition at the end of 1946”. But we need to get the maps right to start with.
Unfortunately, BclDateTimeZone already has complicated code to handle the previously-known corner cases. That makes the whole thing feel quite precarious – I could easily end up breaking other things by trying to fix this one specific aspect. Still, that’s what unit tests are for.
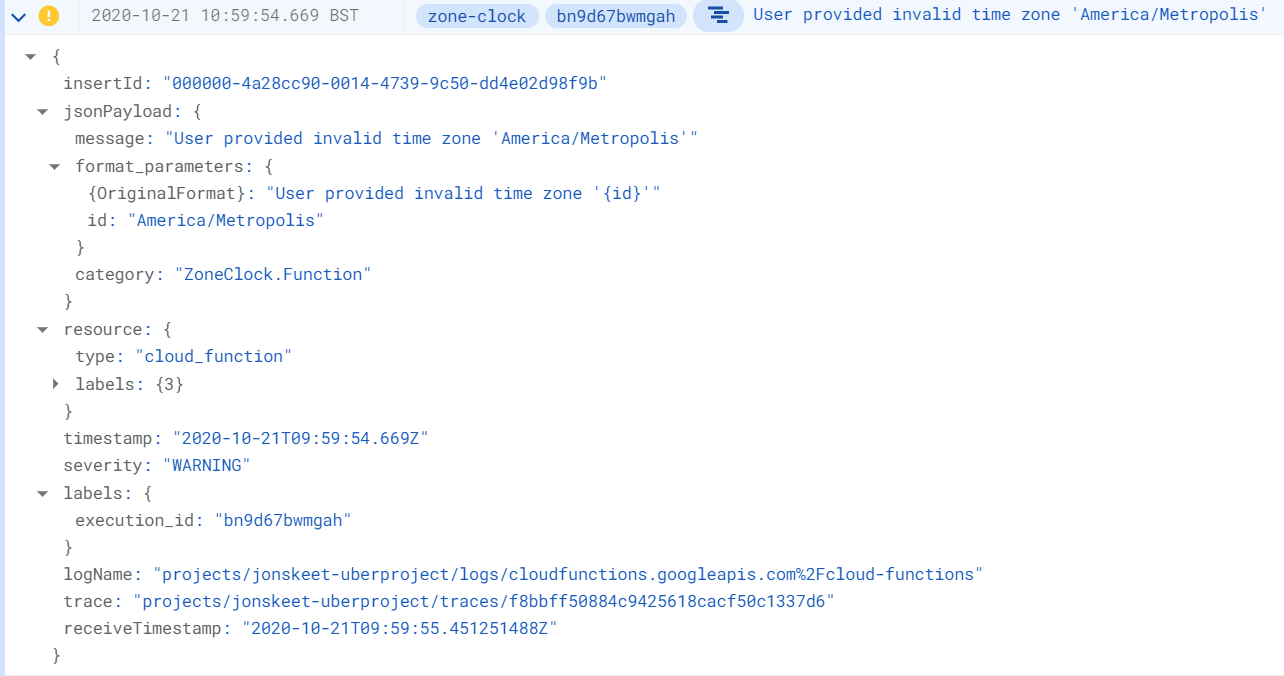
Looking at the code, I suspect the problem is with the start time of the first rule of 1947, which I’d expect to start at 1947-01-01T00:00:00Z, but is actually deemed to start at 1946-12-31T23:00:00Z. (In the course of writing that out, I notice that my improved-abutting-error exception doesn’t include the “Z”. Fix that now…)
Ah… but the UTC start of the rule is currently expected to be “the start date + the transition start time – base UTC offset”. That does give 1946-12-31T23:00:00Z. We want to apply the daylight savings (of -1 hour) in this case, because the start of the rule is during daylight savings. Again, there’s no documentation to say exactly what is meant by “start date” for the rule, and hopefully you can see why it’s really frustrating to have to try to reverse-engineer this in a version-agnostic way. Hmm.
Seeking an unambiguous and independent interpretation of AdjustmentRule
It’s relatively easy to avoid the “maps don’t abut” issue if we don’t care about really doing the job properly. After converting each AdjustmentRule to its Noda Time equivalent, we can look at rule pair of adjacent rules in the sequence: if the start of the “next” rule is earlier than the end of the “previous” rule, we can just adjust the start point. But that’s really just brushing the issue under the carpet – and as it happens, it just moves the exception to a different point.
That approach also requires knowledge of surrounding adjustment rules in order to completely understand one adjustment rule. That really doesn’t feel right to me. We should be able to understand the adjustment rule purely from the data exposed by that rule and the properties for the TimeZoneInfo itself. The code is already slightly grubby by calling TimeZoneInfo.IsDaylightSavingTime(). If I could work out how to remove that call too, that would be great. (It may prove infeasible to remove it for .NET Core 3.1, but feasible in 6. That’s not too bad. Interesting question: if the “grubby” code still works in .NET 6, is it better to use conditional code so that only the “clean” code is used in .NET 6, or avoid the conditional code? Hmm. We’ll see.)
Given that the rules in both .NET Core 3.1 and .NET 6 effectively mean that the start and end points are exactly the start and end points of DST (or other) transitions, I should be able to gather a number of examples of source data and expected results, and try to work out rules from that. In particular, this source data should include:
- “Simple” situations (partly as a warm-up…)
- Negative standard time offset (e.g. US time zones)
- Negative savings (e.g. Prague above, and Europe/Dublin from 1971 onwards)
- DST periods that cross year boundaries (primarily the southern hemisphere, e.g. America/Sao_Paulo)
- Zero savings, but still in DST (Europe/Dublin before 1968)
- Standard UTC offset changes (e.g. Europe/London 1968-1971, Europe/Moscow from March 2011 to October 2014)
- All of the above for both .NET Core 3.1 and .NET 6, including the rules which represent standard time in .NET Core 3.1 but which are omitted in .NET 6
It looks like daylight periods which cross year boundaries are represented as single rules in .NET Core 3.1 and dual rules in .NET 6, so we’ll need to take that into account. In those cases we’ll need to map to two Noda Time rules, and we don’t mind where the transition between them is, so long as they abut. In general, working out the zone intervals that are relevant for a single year may require multiple lines of data from each source. (But we must be able to infer some of that from gaps, and other parts from individual source rules.)
Fortunately we’re not trying to construct “full rules” within Noda Time – just ZoneInterval values, effectively. All we need to be able to determine is:
- Start instant
- End instant
- Standard offset
- Daylight savings (if any)
When gathering the data, I’m going to assume that using the existing Noda Time interpretation of the IANA data is okay. That could be dangerous if either .NET interprets the data incorrectly, or if the Linux data isn’t the same as the IANA 2021e data I’m working from. There are ways to mitigate those risks, but they would be longwinded and I don’t think the risk justifies the extra work.
What’s absolutely vital is that the data is gathered carefully. If I mess this up (looking at the wrong time zone, or the wrong year, or running some code on Windows that I meant to run on Linux – like the earlier tests) it could several hours of work. This will be tedious.
Let’s gather some data…
Europe/Paris in 2020: .NET Core 3.1: Base offset = 1 2019-10-27 - 2020-03-29: Daylight delta: +00; DST starts October 27 at 02:00:00 and ends March 29 at 01:59:59 2020-03-29 - 2020-10-25: Daylight delta: +01; DST starts March 29 at 02:00:00 and ends October 25 at 02:59:59 2020-10-25 - 2021-03-28: Daylight delta: +00; DST starts October 25 at 02:00:00 and ends March 28 at 01:59:59 .NET 6: Base offset = 1 2019-03-31 - 2019-10-27: Daylight delta: +01; DST starts March 31 at 02:00:00 and ends October 27 at 02:59:59.999 2020-03-29 - 2020-10-25: Daylight delta: +01; DST starts March 29 at 02:00:00 and ends October 25 at 02:59:59.999 2021-03-28 - 2021-10-31: Daylight delta: +01; DST starts March 28 at 02:00:00 and ends October 31 at 02:59:59.999 Noda Time zone intervals (start - end, standard, savings): 2019-10-27T01:00:00Z - 2020-03-29T01:00:00Z, +1, +0 2020-03-29T01:00:00Z - 2020-10-25T01:00:00Z, +1, +1 2020-10-25T01:00:00Z - 2021-03-28T01:00:00Z, +1, +0 America/Los_Angeles in 2020: .NET Core 3.1: Base offset = -8 2019-11-03 - 2020-03-08: Daylight delta: +00; DST starts November 03 at 01:00:00 and ends March 08 at 01:59:59 2020-03-08 - 2020-11-01: Daylight delta: +01; DST starts March 08 at 02:00:00 and ends November 01 at 01:59:59 2020-11-01 - 2021-03-14: Daylight delta: +00; DST starts November 01 at 01:00:00 and ends March 14 at 01:59:59 .NET 6: Base offset = -8 2019-03-10 - 2019-11-03: Daylight delta: +01; DST starts March 10 at 02:00:00 and ends November 03 at 01:59:59.999 2020-03-08 - 2020-11-01: Daylight delta: +01; DST starts March 08 at 02:00:00 and ends November 01 at 01:59:59.999 2021-03-14 - 2021-11-07: Daylight delta: +01; DST starts March 14 at 02:00:00 and ends November 07 at 01:59:59.999 Noda Time zone intervals: 2019-11-03T09:00:00Z - 2020-03-08T10:00:00Z, -8, +0 2020-03-08T10:00:00Z - 2020-11-01T09:00:00Z, -8, +1 2020-11-01T09:00:00Z - 2021-03-14T10:00:00Z, -8, +0 Europe/Prague in 1946/1947: .NET Core 3.1: Base offset = 1 1945-10-01 - 1946-05-06: Daylight delta: +00; DST starts October 01 at 02:00:00 and ends May 06 at 01:59:59 1946-05-06 - 1946-10-06: Daylight delta: +01; DST starts May 06 at 02:00:00 and ends October 06 at 02:59:59 1946-10-06 - 1946-12-01: Daylight delta: +00; DST starts October 06 at 02:00:00 and ends December 01 at 02:59:59 1946-12-01 - 1947-02-23: Daylight delta: -01; DST starts December 01 at 03:00:00 and ends February 23 at 01:59:59 1947-02-23 - 1947-04-20: Daylight delta: +00; DST starts February 23 at 03:00:00 and ends April 20 at 01:59:59 1947-04-20 - 1947-10-05: Daylight delta: +01; DST starts April 20 at 02:00:00 and ends October 05 at 02:59:59 1947-10-05 - 1948-04-18: Daylight delta: +00; DST starts October 05 at 02:00:00 and ends April 18 at 01:59:59 1948-04-18 - 1948-10-03: Daylight delta: +01; DST starts April 18 at 02:00:00 and ends October 03 at 02:59:59 .NET 6: Base offset = 1 1945-05-08 - 1945-10-01: Daylight delta: +01; DST starts May 08 at 23:00:00 and ends October 01 at 02:59:59.999 1946-05-06 - 1946-10-06: Daylight delta: +01; DST starts May 06 at 02:00:00 and ends October 06 at 02:59:59.999 1946-12-01 - 1946-12-31: Daylight delta: -01; DST starts December 01 at 03:00:00 and ends December 31 at 23:59:59.999 1947-01-01 - 1947-02-23: Daylight delta: -01; DST starts January 01 at 00:00:00 and ends February 23 at 01:59:59.999 1947-04-20 - 1947-10-05: Daylight delta: +01; DST starts April 20 at 02:00:00 and ends October 05 at 02:59:59.999 1948-04-18 - 1948-10-03: Daylight delta: +01; DST starts April 18 at 02:00:00 and ends October 03 at 02:59:59.999 Noda Time zone intervals: 1945-10-01T01:00:00Z - 1946-05-06T01:00:00Z, +1, +0 1946-05-06T01:00:00Z - 1946-10-06T01:00:00Z, +1, +1 1946-10-06T01:00:00Z - 1946-12-01T02:00:00Z, +1, +0 1946-12-01T02:00:00Z - 1947-02-23T02:00:00Z, +1, -1 1947-02-23T02:00:00Z - 1947-04-20T01:00:00Z, +1, +0 1947-04-20T01:00:00Z - 1947-10-05T01:00:00Z, +1, +1 1947-10-05T01:00:00Z - 1948-04-18T01:00:00Z, +1, +0 Europe/Dublin in 2020: .NET Core 3.1: Base offset = 1 2019-10-27 - 2020-03-29: Daylight delta: -01; DST starts October 27 at 02:00:00 and ends March 29 at 00:59:59 2020-03-29 - 2020-10-25: Daylight delta: +00; DST starts March 29 at 02:00:00 and ends October 25 at 01:59:59 2020-10-25 - 2021-03-28: Daylight delta: -01; DST starts October 25 at 02:00:00 and ends March 28 at 00:59:59 .NET 6.0: Base offset = 1 2019-10-27 - 2019-12-31: Daylight delta: -01; DST starts October 27 at 02:00:00 and ends December 31 at 23:59:59.999 2020-01-01 - 2020-03-29: Daylight delta: -01; DST starts January 01 at 00:00:00 and ends March 29 at 00:59:59.999 2020-10-25 - 2020-12-31: Daylight delta: -01; DST starts October 25 at 02:00:00 and ends December 31 at 23:59:59.999 2021-01-01 - 2021-03-28: Daylight delta: -01; DST starts January 01 at 00:00:00 and ends March 28 at 00:59:59.999 Noda Time zone intervals: 2019-10-27T01:00:00Z - 2020-03-29T01:00:00Z, +1, -1 2020-03-29T01:00:00Z - 2020-10-25T01:00:00Z, +1, +0 2020-10-25T01:00:00Z - 2021-03-28T01:00:00Z, +1, -1 Europe/Dublin in 1960: .NET Core 3.1: Base offset = 1 1959-10-04 - 1960-04-10: Daylight delta: +00; DST starts October 04 at 03:00:00 and ends April 10 at 02:59:59 1960-04-10 - 1960-10-02: Daylight delta: +00; DST starts April 10 at 03:00:00 and ends October 02 at 02:59:59 .NET 6.0: Base offset = 1 1959-10-04 - 1959-12-31: Base UTC offset delta: -01; Daylight delta: +00; DST starts October 04 at 03:00:00 and ends December 31 at 23:59:59.999 1960-01-01 - 1960-04-10: Base UTC offset delta: -01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends April 10 at 02:59:59.999 1960-04-10 - 1960-10-02: Daylight delta: +00; DST starts April 10 at 03:00:00 and ends October 02 at 02:59:59.999 1960-10-02 - 1960-12-31: Base UTC offset delta: -01; Daylight delta: +00; DST starts October 02 at 03:00:00 and ends December 31 at 23:59:59.999 1961-01-01 - 1961-03-26: Base UTC offset delta: -01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends March 26 at 02:59:59.999 Noda Time zone intervals: 1959-10-04T02:00:00Z - 1960-04-10T02:00:00Z, +0, +0 1960-04-10T02:00:00Z - 1960-10-02T02:00:00Z, +0, +1 1960-10-02T02:00:00Z - 1961-03-26T02:00:00Z, +0, +0 America/Sao_Paulo in 2018 (not 2020, as Brazil stopped observing daylight savings in 2019): .NET Core 3.1: Base offset = -3 2017-10-15 - 2018-02-17: Daylight delta: +01; DST starts October 15 at 00:00:00 and ends February 17 at 23:59:59 2018-02-17 - 2018-11-03: Daylight delta: +00; DST starts February 17 at 23:00:00 and ends November 03 at 23:59:59 2018-11-04 - 2019-02-16: Daylight delta: +01; DST starts November 04 at 00:00:00 and ends February 16 at 23:59:59 .NET 6.0: Base offset = -3 2017-10-15 - 2017-12-31: Daylight delta: +01; DST starts October 15 at 00:00:00 and ends December 31 at 23:59:59.999 2018-01-01 - 2018-02-17: Daylight delta: +01; DST starts January 01 at 00:00:00 and ends February 17 at 23:59:59.999 2018-11-04 - 2018-12-31: Daylight delta: +01; DST starts November 04 at 00:00:00 and ends December 31 at 23:59:59.999 2019-01-01 - 2019-02-16: Daylight delta: +01; DST starts January 01 at 00:00:00 and ends February 16 at 23:59:59.999 Noda Time zone intervals: 2017-10-15T03:00:00Z - 2018-02-18T02:00:00Z, -3, +1 2018-02-18T02:00:00Z - 2018-11-04T03:00:00Z, -3, +0 2018-11-04T03:00:00Z - 2019-02-17T02:00:00Z, -3, +1 Europe/London in 1968-1971 .NET Core 3.1: Base offset = 0 1968-10-26 - 1971-10-31: Daylight delta: +00; DST starts October 26 at 23:00:00 and ends October 31 at 01:59:59 .NET 6: Base offset = 0 1968-10-26 - 1968-12-31: Base UTC offset delta: +01; Daylight delta: +00; DST starts October 26 at 23:00:00 and ends December 31 at 23:59:59.999 1969-01-01 - 1970-12-31: Base UTC offset delta: +01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends December 31 at 23:59:59.999 1971-01-01 - 1971-10-31: Base UTC offset delta: +01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends October 31 at 01:59:59.999 Noda Time zone intervals: 1968-10-26T23:00:00Z - 1971-10-31T02:00:00Z, +1, +0 Europe/Moscow in 2011-2014 .NET Core 3.1: Base offset = 3 2011-03-27 - 2014-10-26: Daylight delta: +00; DST starts March 27 at 02:00:00 and ends October 26 at 00:59:59 .NET 6: Base offset = 3 2011-03-27 - 2011-12-31: Base UTC offset delta: +01; Daylight delta: +00; DST starts March 27 at 02:00:00 and ends December 31 at 23:59:59.999 2012-01-01 - 2013-12-31: Base UTC offset delta: +01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends December 31 at 23:59:59.999 2014-01-01 - 2014-10-26: Base UTC offset delta: +01; Daylight delta: +00; DST starts January 01 at 00:00:00 and ends October 26 at 00:59:59.999 Noda Time zone intervals: 2011-03-26T23:00:00Z - 2014-10-25T22:00:00Z, +4, +0
I think that forcing myself to collect these small bits of data and write them down will be a bit of a game-changer. Previously I’ve taken handwritten notes for individual issues, relying on the “global” unit tests (check every transition in every time zone) to catch any problems after I’d implemented them. But with the data above, I can write unit tests. And those unit tests don’t need to depend on whether we’re running on Windows and Linux, which will make the whole thing much simpler. We’re not testing an actual time zone – we’re testing “adjustment rule to Noda Time representation” with adjustment rules as they would show up on Linux.
There’s one slightly fiddly bit: I suspect that detecting “base UTC offset delta” for .NET Core 3.1 will require the time zone itself (as we can’t get to the rule data). I might get all the rest of the unit tests working first (and even the non-zero-delta ones for .NET 6) and come back to that.
That’s all for now…
I’ve now implemented the above test data in uncommitted code. After starting to include strings directly into the code, I’ve decided to put all the test data in a text file, pretty much as it’s specified above (just with very minor formatting changes). This is going to be really handy in terms of having readable test cases; I’m already glad I’ve put the effort into it.
However, I’ve discovered that it’s incomplete, as we need test cases for offset changes across the international date line (in both directions). It’s also possible that the choice of America/Sao_Paulo is unfortunate, as Brazil changed clocks at midnight. We might want an example in Australia as well. (Potentially even two: one with whole hour offsets and one with half hour offsets.)
Even without that additional test, there are issues. I can get all but “Europe/Dublin in 1968” to work in .NET 6. I haven’t yet worked out how to handle changing standard offsets in .NET Core 3.1 in a testable way. Even the fact that standard offsets can change is a pain, in terms of working out the transition times in .NET 6, as it appears to be something like “Assume the start is in standard time and the end is in daylight time, except don’t take any standard time deltas into account when calculating that” – which is very weird indeed. (And I don’t understand how the Europe/Dublin data in .NET 6 is meant to convey the expected data. It’s very odd.)
This post is quite long enough though, so I’m going to post it now and take a break from time zones for a bit. Hopefully I’ll post a “part 2” when I’ve actually got everything working.
Just as a reminder, supposedly these changes in .NET 6: “don’t affect external behavior, other than to ensure correctness in some edge cases”. Mmm. Really.