This is a blog post I’ve intended to write for a very long time. (Other blog posts in that category include a recipe for tiramisu ice cream, and “knights and allies”.) It’s one of those things that’s grown in my mind over time, becoming harder and harder to start. However, there have been three recent incidents that have brought it back into focus:
- Azure Functions and Grpc.Core versioning conflict
- Grpc.Core considering a major version bump
- Recent internal discussions that would involve a major version bump for all the Google Cloud libraries I maintain
TL;DR: Versioning is inherently hard, but the way that .NET infrastructure is set up makes it harder than it needs to be, I suspect.
The sample code for this blog post is available on GitHub.
Refresher: SemVer
NuGet is the de facto standard for distribution of packages now, and it supports semantic versioning, also known as SemVer for short. SemVer version strings (ignoring pre-release versions) are of the form major.minor.patch.
The rules of SemVer sound straightforward from the perspective of a package producer:
- If you make a breaking change, you need to bump the major version
- If you make backward compatible additions, you need to bump the minor version
- If you make backward and forward compatible changes (basically internal implementation changes or documentation changes) you bump the patch version
It also sounds straightforward from the perspective of a package consumer, considering moving from one version to another of a package:
- If you move to a different major version, your existing code may not work (because everything can change between major versions)
- If you move to a later minor version within the same major version, your code should still work
- If you move to an earlier minor version within the same major version, your existing code may not work (because you may be using something that was introduced in the latest minor version)
- If you move to a later or earlier patch version within the same major/minor version, your code should still work
Things aren’t quite as clear as they sound though. What counts as a breaking change? What kind of bug fix can go into just a patch version? If a change can be detected, it can break someone, in theory at least.
The .NET Core team has a set of rules about what’s considered breaking or not. That set of rules may not be appropriate for every project. I’d love to see:
- Tooling to tell you what kind of changes you’ve made between two commits
- A standard format for rules so that the tool from the first bullet can then suggest what your next version number should be; your project can then advertise that it’s following those rules
- A standard format to record the kinds of changes made between versions
- Tooling to check for “probable compatibility” of the new version of a library you’re consuming, given your codebase and the record of changes
With all that in place, we would all hopefully be able to follow SemVer reliably.
Importantly, this makes the version number a purely technical decision, not a marketing one. If the current version of your package is (say) 2.3.0, and you add a bunch of features in a backward-compatible way, you should release the new version as 2.4.0, even if it’s a “major” version in terms of the work you’ve put in. Use whatever other means you have to communicate marketing messages: keep the version number technical.
Even with packages that follow SemVer predictably and clearly, that’s not enough for peace and harmony in the .NET ecosystem, unfortunately.
The diamond dependency problem
The diamond dependency problem is not new to .NET, and most of the time we manage to ignore it – but it’s still real, and is likely to become more of an issue over time.
The canonical example of a diamond dependency is where an application depends on two libraries, each of which depends on a common third library, like this:
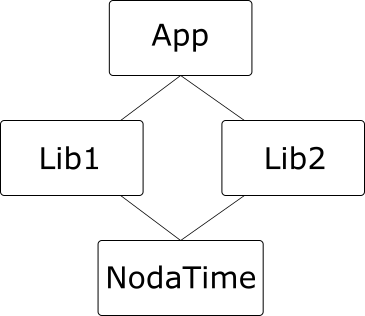
(I’m using NodaTime as an example so I can refer to specific versions in a moment.)
It doesn’t actually need to be this complicated – we don’t need Lib2 here. All we need is two dependencies on the same library, and one of those can be from the application:
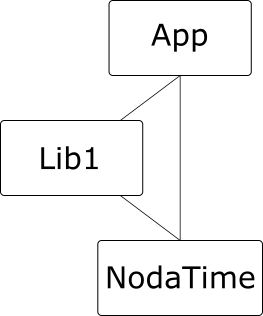
Multiple dependencies on the same library are fine, so long as they depend on compatible versions. For example, from our discussion of SemVer above, it should be fine for Lib1 to depend on NodaTime 1.3.0, and App to depend on NodaTime 1.2.0. We expect the tooling to resolve all the dependencies and determine that 1.3.0 is the version to use, and the App code should be fine with that – after all, 1.3.0 is meant to be backward-compatible with 1.2.0. The same is true the other way round, if App depends on later version than Lib1, so long as they’re using the same major version.
(Note: there are potential problems even within a minor version number – if App depends on 1.3.0 and Lib1 depends on 1.3.1 which contains a bug fix, but App has a workaround for the bug which then fails under 1.3.1 when the bug is no longer present. Things like that can definitely happen, but I’ll ignore that kind of problem for the rest of this post, and assume that everything conforms to idealized SemVer.)
Diamond dependencies become a problem under SemVer when the dependencies are two different major versions of the same library. To give a concrete example from the NodaTime package, consider the IClock interface. The 1.4.x version contains a single property, Now. The 2.0.x version has the same functionality, but as a method, GetCurrentInstant(). (This was basically a design failing on my part in v1 – I followed the BCL example of DateTime.Now without thinking clearly enough about whether it should have been a property.)
Now suppose App is built with the .NET Core SDK, and depends on NodaTime 2.0.0, and Lib1 depends on NodaTime 1.3.1 – and let’s imagine a world where that was the only breaking change in NodaTime 2.x. (It wasn’t.) When we build the application, we’d expect 2.0 to be used at execution time. If Lib1 never calls IClock.Now, all is well. Under .NET Core tooling, assembly binding redirects are handled automatically so when Lib1 “requests” NodaTime 1.3.1, it gets NodaTime 2.0.0. (The precise way in which this is done depends on the runtime executing the application. In .NET Core, there’s an App.deps.json file; in desktop .NET it’s App.exe.config. Fortunately this doesn’t matter much at the level of this blog post. It may well make a big difference to what’s viable in the future though.)
If Lib1 does call IClock.Now, the runtime will throw a MissingMethodException. Ouch. (Sample code.)
The upshot is that if the transitive set of “package + version” tuples for your entire application contains more than one major version for the same package, it’s entirely possible that you’ll get an exception at execution time such as MissingMethodException, MissingFieldException, TypeNotFoundException or similar.
If that doesn’t sound too likely, please consider that the Newtonsoft.Json package (Json .NET) has 12 major versions as I’m writing this blog post. I suspect that James Newton-King has kept the breaking changes to an absolute minimum, but even so, it’s pretty scary.
Non-proposals
I’d like to propose some enhancements to tooling that might help to address the issue. Before we look at what I am suggesting, I’d like to mention a few options that I’m not suggesting.
Ignore the problem
I’m surprised that few people seem as worried about versioning as I am. I’ve presented talks on versioning a couple of times, but I don’t remember seeing anyone else do so – and certainly not in a .NET-specific deep-dive way. (My talk isn’t that, either.) It’s possible that there are lots of people who are worried, and they’re just being quiet about it.
This blog post is just part of me trying to agitate the community – including but not limited to Microsoft – into taking this problem seriously. If it turns out that there are already smart people working on this, that’s great. It’s also possible that we can live on the edge of versioning anarchy forever and it will always be a potential nightmare, but only cause a small enough number of failures that we decide we can live with it. That feels like a risk we should at least take consciously though.
Build at head, globally
In 2017, Titus Winters presented C++ as a live at head language at CppCon. It’s a great talk; go watch it. (Yes, it’s an hour and a half long. It’s still worth it. It also states a bunch of what I’ve said above in a slightly different way, so it may be helpful in that sense.) The idea is for everyone to build their application based on full source code, and provide tooling to automatically update consumer code based on library changes.
To go back to the Noda Time IClock example, if I build all the code for my application locally (App, Lib1 and NodaTime) then when NodaTime changes from the IClock.Now property to IClock.GetCurrentInstant(), the code in Lib1 that uses IClock.Now can automatically be changed to use IClock.GetCurrentInstant(), and everyone is happy with the same version. The Abseil project is a library (or collection of libraries) for C++ that embrace this concept.
It’s possible that this could eventually be a good solution for .NET. I don’t know of any technical aspects that mean it could work for C++ but not for .NET. However, it’s so far from our current position that I don’t believe it’s a practical choice at the moment, and I think it makes sense to try this experiment in one language first for a few years, then let other languages consider whether it makes sense for them.
I want to make it very clear that I’m not disagreeing with anything Titus said. He’s a very smart guy, and I explicitly do agree with almost everything I’ve heard him say. If I ever decide that I disagree with some aspect and want to make a public debate about it, I’ll be a lot more specific. Vague arguments are irritating for everyone. But the .NET ecosystem does depend on binary distribution of packages at the moment, and that’s an environment Titus deliberately doesn’t try to address. If someone wants to think about all the practical implications of all the world’s .NET consumers living at head in a source-driven (rather than binary-driven) world, I’d be interested in reading the results of that thinking. It’s certainly more feasible now than it was before .NET Core. But I’m not going there right now.
Never make breaking changes in any library
If we never make any changes that will break anyone, none of this is a problem.
I gave the example of Newtonsoft.Json earlier, and that it’s on major version 12. My guess is that that means there really have been 11 sets of breaking changes, but that they’re sufficiently unlikely to cause real failure that we’ve survived.
In the NodaTime package, I know I have made real breaking changes – it’s currently at version 2.4.x, and I’m planning on a 3.0 release some time after C# 8 comes out. I’ve made (or I’m considering) breaking changes in at least three different ways:
- Adding members to public interfaces. If you implement those interfaces yourself (which is relatively unlikely) your code will be broken. On the other hand, everyone who wants the functionality I’ve added gets to use it in a clean way.
- Removing functionality which is either no longer desirable (binary serialization) or shouldn’t have been present to start with. If you still want that functionality, I can only recommend that you stay on old versions.
- Refactoring existing functionality, e.g. the
IClock.Now=>IClock.GetCurrentInstant()change, or fixing a typo in a method name. It’s annoying for existing consumers, but better for future consumers.
I want to be able to make all of these changes. They’re all good things in the long run, I believe.
So, those are options I don’t want to take. Let’s look at a few that I think we should pursue.
Proposals
Firstly, well done and thank you for making it this far. Before any editing, we’re about 2000 words into the post at this point. A smarter person might have got this far quicker without any loss of important information, but I hope the background has been useful.
Prerequisite: multi-version support
My proposals require that the runtime support loading multiple assemblies with the same name at the same time. Obviously I want to support .NET Core, so this mustn’t require the use of multiple AppDomains. As far as I’m aware, this is already the case, and I have a small demo of this, running with both net471 and netcoreapp2.0 targets:
// Call SystemClock.Instance.Now in NodaTime 1.3.1
string path131 = Path.GetFullPath("NodaTime-1.3.1.dll");
Assembly nodaTime131 = Assembly.LoadFile(path131);
dynamic clock131 = nodaTime131
.GetType("NodaTime.SystemClock")
// Instance is a field 1.x
.GetField("Instance")
.GetValue(null);
Console.WriteLine(clock131.Now);
// Call SystemClock.Instance.GetCurrentInstant() in NodaTime 2.0.0
string path200 = Path.GetFullPath("NodaTime-2.0.0.dll");
Assembly nodaTime200 = Assembly.LoadFile(path200);
dynamic clock200 = nodaTime200
.GetType("NodaTime.SystemClock")
// Instance is a property in 2.x
.GetProperty("Instance")
.GetValue(null);
Console.WriteLine(clock200.GetCurrentInstant());
I’ve used dynamic typing here to avoid having to call the Now property or GetCurrentInstant() method using hand-written reflection, but we have to obtain the clock with reflection as it’s accessed via a static member. This is in a project that doesn’t depend on Noda Time at all in a compile-time sense. It’s possible that introducing a compile-time dependency could lead to some interesting problems, but I suspect those are fixable with the rest of the work below.
On brief inspection, it looks like it’s also possible to load two independent copies of the same version of the same assembly, so long as they’re stored in different files. That may be important later on, as we’ll see.
Proposal: execute with the expected major version
The first part of my proposal underlies all the rest. We should ensure that each library ends up executing against a dependency version that has the same major version it requested. If Lib1 depends on Noda Time 1.3.1, tooling should make sure it always gets >= 1.3.1 and = 1.3.1″ which appears to be the default at the moment, but I don’t mind too much if I have to be explicit. The main point is that when different dependencies require different major versions, the result needs to be multiple assemblies present at execution time, rather than either a build error or the approach of “let’s just hope that Lib1 doesn’t use anything removed in 2.0”. (Of course, Lib1 should be able to declare that it is compatible with both NodaTime 1.x and NodaTime 2.x. It would be good to make that ease to validate, too.)
If the rest of the application already depends on NodaTime 1.4.0 (for example) then it should be fine to stick to the simple situation of loading a single copy of the NodaTime assembly. But if the rest of the application is using 2.0.0 but Lib1 depends on 1.3.1, we should make that work by loading both major versions 1 and 2.
This proposal then leads to other problems in terms of how libraries communicate with each other; the remaining proposals attempt to address that.
Proposal: private dependencies
When describing the diamond dependency problem, there’s one aspect I didn’t go into. Sometimes a library will take a dependency as a pure implementation detail. For example, Lib1 could use NodaTime internally, but expose an API that’s purely in terms of DateTime. On the other hand, Lib1 could expose its use of NodaTime via its public (and protected) API, using NodaTime types for some properties, method parameters, method return types, generic type arguments, base types and so on.
Both scenarios are entirely reasonable, but they have different versioning concerns. If Lib1 uses NodaTime as a “private dependency” then App shouldn’t (in an ideal world) need to care which version of NodaTime Lib1 uses.
However, if Lib1 exposes method with an IClock parameter, the method caller really needs to know that it’s using a 1.3.1. They’ll need to have a “1.3.1 IClock” to pass in. That means App needs to be aware of the version of NodaTime that Lib1 depends on.
I propose that the author of Lib1 should be able to make a decision about whether NodaTime is a “public” or “private” dependency, and express that decision within the NuGet package.
The compiler should be able to validate that a private dependency really isn’t exposed in the public API anywhere. Ideally, I’d like this to be part of the C# language eventually; I think versioning is important enough to be a language concern. It’s reasonable to assert that that ship has sailed, however, and that it’s reasonable to just have a Roslyn analyzer for this. Careful thought is required in terms of transitive dependencies, by the way. How should the compiler/analyzer treat a situation where Lib1 privately depends on NodaTime 1.3.1, but publicly depends on Lib2 that publicly depends on NodaTime 2.0.0? I confess I haven’t thought this through in detail; I first want to get enough people interested that the detailed work is worth doing.
Extern aliases for packages
Private dependencies are relatively simple to think about, I believe. They’re implementation details that should – modulo a bunch of caveats – not impact consumers of the library that has the private dependencies.
Public dependencies are trickier. If App wants to use NodaTime 2.0.0 for almost everything, but needs to pass in a 1.3.1 clock to a method in Lib1, then App effectively needs to depend on both 1.3.1 and 2.0.0. Currently, as far as I’m aware, there’s no way of representing this in a project file. C# as a language supports the idea of multiple assemblies exposing the same types, via extern aliases… but we’re missing a way of expressing that in project files.
There’s already a GitHub issue requesting this, so I know I’m not alone in wanting it. We might have something like:
<ProjectReference Include="NodaTime" Version="1.3.1" ExternAlias="noda1" /> <ProjectReference Include="NodaTime" Version="2.0.0" ExternAlias="noda2" />
then in the C# code you might use:
using noda2::NodaTime; // Use NodaTime types as normal, using NodaTime 2.0.0 // Then pass a 1.3.1 clock into a Lib1 method: TypeFromLib1.Method(noda1::NodaTime.SystemClock.Instance);
There’s an assumption here: that each package contains a single assembly. That definitely doesn’t have to be true, and a full solution would probably need to address that, allowing more complex syntax for per-assembly aliasing.
It’s worth noting that it would be feasible for library authors to providing “bridging” packages too. For example, I could provide a NodaTime.Bridging package which allowed you to convert between NodaTime 1.x and NodaTime 2.x types. Sometimes those conversions may be lossy, but they’re at least feasible. The visible immutability of almost every type in Noda Time is a big help here, admittedly – but packages like this could really help consumers.
Here be dragons: shared state
So far I’ve thought of two significant problems with the above proposals, and both involve shared state – but in opposite directions.
Firstly, consider singletons that we really want to be singletons. SystemClock.Instance is a singleton in Noda Time. But if multiple assemblies are loaded, one per major version, then it’s really “singleton per major version.” For SystemClock that’s fine, but imagine if your library decided that it would use grab a process-wide resource in its singleton, assuming that it was okay to do so because after all there’s only be one of them. Maybe you’d have an ID generator which would guarantee uniqueness by incrementing a counter. That doesn’t work if there are multiple instances.
Secondly, we need to consider mutable shared state, such as some sort of service locator that code registered implementations in. Two different libraries with supposedly private dependencies on the same service locator package might each want to register the same type in the service locator. At that point, things work fine if they depend on different major versions of the service locator package, but start to conflict if the implementations happen to depend on the same major version, and end up using the same assembly. Our isolation of the private dependency isn’t very isolated after all.
While it’s reasonable to argue that we should avoid this sort of shared state as far as possible, it’s unreasonable to assume that it doesn’t exist, or that it shouldn’t be considered as part of this kind of versioning proposal. At the very least, we need to consider how users can diagnose issues stemming from this with some ease, even if I suspect it’ll always be slightly tricky.
As noted earlier, it’s possible to introduce more isolation by loading the same assembly multiple times, so potentially each private dependency could really be private. That helps in the second case above, but hurts more in the first case. It also has a performance impact in terms of duplication of code etc.
Here be unknown dragons
I’m aware that versioning is really complicated. I’ve probably thought about it more than most developers, but I know there’s a lot I’m unaware of. I don’t expect my proposals to be “ready to go” without serious amounts of detailed analysis and work. While I would like to help with that work, I suspect it will mostly be done by others.
I suspect that even this detailed analysis won’t be enough to get things right – I’d expect that when there’s a prototype, exposing it to real world dependencies will find a bunch more issues.
Conclusion
I believe the .NET ecosystem has a versioning problem that’s currently not being recognized and addressed.
The intention isn’t that these proposals are final, concrete design docs – the intention is that they help either start the ball rolling, or give an already-rolling-slightly ball a little more momentum. I want the community to openly discuss the problems we’re seeing now, so we get a better handle on the problem, and then work together to alleviate those problems as best we can, while recognizing that perfection is unlikely to be possible.
