This post revisits the problem described in Versioning Limitations in .NET, based on reactions to that post and a Twitter discussion which occurred later.
Before getting onto the main topic of the post, I wanted to comment a little on that Twitter discussion. I personally found it frustrating at times, and let that frustration leak out into some of my responses. As Twitter debates go, this was relatively mild, but it was still not as constructive as it might have been, and I take my share of responsibility for that. Sorry, folks. I’m sure that everyone involved – both in that Twitter discussion and more generally in the .NET community – genuinely wants the best outcome here. I’ve attempted to frame this post with that thought at the top of mind, assuming that all opinions on the topic are held and expressed in good faith. As you’ll see, that doesn’t mean I have to agree with everyone, but it hopefully helps me respect arguments I disagree with. I’m happy to make corrections (probably with some sort of history) if I misrepresent things or miss out some crucial pros/cons. The goal of this post is to help the community weigh up options as pragmatically as possible.
Scope, terminology and running example
There are many aspects to versioning, of course. In the future I plan to blog about some interesting impacts of multi-targeting libraries, and the choices involved in writing one library to effectively augment another. But those are topics for another day.
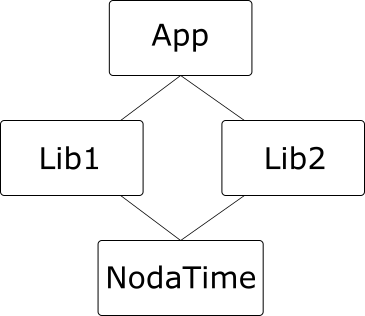
The primary situation I want to explore in this post is the problem of breaking changes, particularly with respect to the diamond dependency problem. I’ve found it helpful to make things very, very concrete when it comes to versioning. So we’ll consider the following situation.
- A team is building an application called Time Zone Magic. They’re using .NET Core 3.0, and everything they need to use targets .NET Standard 2.0 – so they have no problems there.
- The team is completely in control of the application, and doesn’t need to worry about any versioning for the application itself. (Just to simplify things…)
- The application depends on Noda Time, naturally, for all the marvellous ways in which Noda Time can help you with time zones.
- The application also depends on DarkSkyCore1.
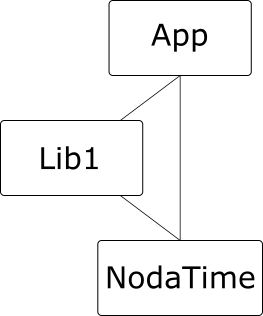
Now DarkSkyCore depends on NodaTime 2.4.7. But the Time Zone Magic application needs to depend on NodaTime 3.0.0 to take advantage of some of the newest functionality. (To clarify, NodaTime 3.0.0 hasn’t actually been released at the time of writing this blog post. This part is concrete but fictional, just like the application itself.) So, we have a diamond dependency problem. It’s entirely possible that DarkSkyCore depends on functionality that’s in NodaTime 2.4.7 but has been removed from 3.0.0. If that’s the case, with the current way .NET works (whether desktop or Core), an exception will occur at some point – exactly how that’s surfaced will probably vary based on a number of factors that I don’t explore in this post.
Currently, as far as I can tell, DarkSkyCore doesn’t refer to any NodaTime types in its public API. We’ll consider what difference this makes in the various options under consideration. I’ll mention a term that I learned during the Twitter conversation: type exchange. I haven’t seen a formal definition of this, but I’m assuming it means one library referring to a type from another library within its public API, e.g. as a parameter or return type, or even as a base class or implemented interface.
The rest of this post consists of some options for what could happen, instead of the current situation. These are just the options I’ve considered; I certainly don’t want to give the impression it’s exhaustive or that we (as a community) should stop trying to think of other options too.
1 I’ve never used this package, and have no opinion on it. It’s just a plausible package to use that depends on NodaTime.
Option 1: Decide to do nothing
It’s always including the status quo as a possible option. We can acknowledge that the current situation has problems (the errors thrown at hard-to-predict places) but we may consider that every alternative is worse, either in terms of end result or cost to implement.
It’s worth bearing in mind that .NET has been around for nearly 20 years, and while this is certainly a known annoyance, I seem to care about it more than most developers I encounter – suggesting that this problem doesn’t make all development on .NET completely infeasible.
I do believe it will hinder the community’s growth in the future though, particularly if (as I hope) the Open Source ecosystem flourishes more and more. I believe one of the reasons this hasn’t bitten the platform very hard so far is that the framework provides so much, and ASP .NET (including Core) dominate on the web framework side of things. In the future, if there are more small, “do one thing well” packages that are popular, the chances of incompatibilities will increase.
Option 2: Never make breaking changes
If we never make breaking changes, there can’t be any incompatibilities. We keep the major version at 1, and it doesn’t matter which minor version anyone depends on.
This has been the approach of the BCL team, very largely (aside from “keeping the major version at 1”) – and is probably appropriate for absolutely “system level” packages. Quite what counts as “system level” is an open question: Noda Time is relatively low level, and attempts to act as a replacement for system types, so does that mean I should never make any breaking changes either?
I could potentially commit to not making any future breaking changes – but deciding to do that right from day 1 would seriously stifle innovation. Releasing version 1.0 is scary enough as it is, without the added pressure of “you own every API mistake in here, forever.” There’s a huge cost involved in the kind of painstaking review of every API element that the BCL team goes through. That’s a cost most open source authors probably can’t bear, and it’s not going to be a good investment of time for 99.9% of libraries… but for the 0.1% that make it and become Json.NET-like in terms of ubiquity, it would be great.
Maybe open source projects should really aim for 2.infinity: version 1.x is to build momentum, and 2.x is forever. Even that leaves me pretty uncomfortable, to be honest.
There’s another wrinkle in this in terms of versioning that may be relevant: platform targeting. One of the reasons I’ve taken a major version bump for NodaTime 3.0 is that I’m dropping support for older versions of .NET. As of NodaTime 3.0, I’m just targeting .NET Standard 2.0. Now that’s a breaking change in that it stops anyone using a platform that doesn’t support .NET Standard 2.0 from taking a dependency on NodaTime 3.0, but it doesn’t have the same compatibility issues as other breaking changes. If the only thing I did for NodaTime 3.0 was to change the target framework, the diamond dependency problem would be a non-issue, I believe: any code that could run 3.0 would be compatible with code expecting 2.x.
Now in Noda Time 3.0 I also removed binary serialization, and I’d be very reluctant not to do that. Should the legacy of binary serialization haunt a library forever? Is there actually some acceptable deprecation period for things like this? I’m not sure.
Without breaking changes, type exchange should always be fine, barring code that relies on bugs in older versions.
Option 3: Put the major version in the package name
The current versioning guidance from Microsoft suggests following SemVer 2.0, but in the breaking changes guidance it states:
CONSIDER publishing a major rewrite of a library as a new NuGet package.
Now, it’s not clear to me what’s considered a “major rewrite”. I implemented a major rewrite of a lot of Noda Time functionality between 1.2 and 1.3, without breaking the API. For 2.0 there was a more significant rewrite, with some breaking changes when we moved to nanosecond precision. It’s worth at least considering the implications of interpreting that as “consider publishing a breaking change as a new NuGet package”. This is effectively putting the version in the package name, e.g. NodaTime1, NodaTime2 etc.
At this point, on a per-package basis, we have no breaking changes, and we’d keep the major version at 1 forever, aside from potentially dropping support for older target platforms, as described in option 2. The differences are:
- The package names become pretty ugly, in my opinion – something that I’d argue is inherently part of the version number has leaked elsewhere. It’s effectively an admission that .NET and SemVer don’t play nicely together.
- We don’t see breaking changes in the app example above, because DarkSkyCore would depend on NodaTime2 and the Time Zone Magic application would depend directly on NodaTime3.
- Global state becomes potentially more problematic: any singleton in both NodaTime2 and NodaTime3 (such as
DateTimeZoneProviders.Tzdbfor NodaTime) would be a “singleton per package” but not a “global singleton”. With the example ofDateTimeZoneProviders.Tzdb, that means different parts of Time Zone Magic could give different results for the same time zone ID, based on whether the data was retrieved via NodaTime2 or NodaTime3. Ouch. - Type exchange doesn’t work out of the box: if DarkSkyCore exposed a NodaTime2 type in its API, the Time Zone Magic code wouldn’t be able to take that result and pass it into NodaTime3 code. On the other hand, it would be feasible to create another package, NodaTime2To3 which depended on both NodaTime2 and NodaTime3 and provided conversions where feasible.
- Having largely-the-same code twice in memory could have performance implications – twice as much JITting etc. This probably isn’t a huge deal in most scenarios, but could be painful in some cases.
No CLR changes are required for this – it’s an option that anyone can adopt right now.
One point that’s interesting to note (well, I think so, anyway!) is that in the Google Cloud Client Libraries we already have a version number in the package name: it’s the version number of the network API that the client library targets. For example, Google.Cloud.Speech.V1 targets the “Speech V1” API. This means there can be a “Speech V2” API with a different NuGet package, and the two packages can be versioned entirely independently. (And you can use both together.) That feels appropriate to me, because it’s part of “the purpose of the package” – whereas the version number of the package itself doesn’t feel right being in the package name.
Option 4: Major version isolation in the CLR
This option is most simply described as “implicit option 3, handled by tooling and the CLR”. (If you haven’t read option 3 yet, please do so now.) Imagine we kept the package name as just NodaTime, but all the tooling involved (MSBuild, NuGet etc) treated “NodaTime v2.x” and “NodaTime v3.x” as independent packages. All the benefits and drawbacks of option 3 would still apply, except the drawback of the version number leaking into the package name.
It’s possible that no CLR changes would be required for this – I don’t know. One of the interesting aspects on the Twitter thread was that AssemblyLoadContext could be used in .NET Core 3 for some of what I’d been describing, but that there were performance implications. Microsoft engineers also reported that what I’d been proposing before would be a huge amount of work and complexity. I have no reason to doubt their estimation here.
My hunch is that if 90% of this could be done in tooling, we should be able to achieve a lot without execution-time penalties. Maybe we’d need to do something like using the major version number as a suffix on the assembly filename, so that NodaTime2.dll and NodaTime3.dll could live side-by-side in the same directory. I could live with that – although I readily acknowledge that it’s a hugely disruptive change. Whatever the implementation, the lack of type exchange would be very disruptive, to the extent that maybe this should be an opt-in (on the part of the package owner) mechanism. “I want more freedom for major version coexistence, at the expense of type exchange.”
Another aspect of feedback in the Twitter thread was that the CLR has supported side-by-side assembly loading for a very long time (forever?) but that customers didn’t use it in practice. Again, I have no reason to dispute the data – but I would say that it’s not evidence that it’s a bad feature. Even great features need to be exposed well before they’ll be used… look at generic variance in the CLR, which was already present in .NET 2.0, but was effectively unused until languages (e.g. C# 4) and the framework (e.g. interfaces such as a IEnumerable) supported it too.
It took a long time to get from “download a zip file, copy the DLLs to a lib directory, and add a reference to that DLL” to “add a reference to a versioned NuGet package which might require its own NuGet dependencies”. I believe many aspects of the versioning story aren’t really exposed in that early xcopy-dependency approach, and so maybe we didn’t take advantage of the CLR facilities nearly as early as we should have don.
If you hadn’t already guessed, this option is the one I’d like to pursue with the most energy. I want to acknowledge that it’s easy for me to write that in a blog post, with none of the cost of fully designing, implementing and supporting such a scheme. Even the exploratory work to determine the full pros and cons, estimate implementation cost etc would be very significant. I’d love the community to help out with this work, while realizing that Microsoft has the most experience and data in this arena.
Option 5: Better error detection
When laying out the example, I noted that for the purposes of DarkSkyCore, NodaTime 2.4.7 and NodaTime 3.0 may be entirely compatible. DarkSkyCore may not need any of the members that have been removed in 3.0. More subtly, even if there are areas of incompatibility, the parts of DarkSkyCore that are accessed by the Time Zone Magic application may not trigger those incompatibilities.
One relatively simple (I believe) first step would be to have a way of determining the first kind of “compatibility despite a major version bump”. I expect that with Mono.Cecil or similar packages, it should be feasible to:
- List every public member (class, struct, interface, method, property etc) present in NodaTime 3.0, by analyzing NodaTime.dll
- List every public member from NodaTime 2.4.7 used within DarkSkyCore, by analyzing DarkSkyCore.dll
- Check whether there’s anything in the second list that’s not in the first. If there isn’t, DarkSkyCore is probably compatible with NodaTime 3.0.0, and Time Zone Magic will be okay.
This ignores reflection of course, along with breaking behavioral changes, but it would at least give a good first indicator. Note that if we’re primarily interested in binary compatibility rather than source compatibility, there are lots of things we can ignore, such as parameter names.
It’s very possible that this tooling already exists, and needs more publicity. Please let me know in comments if so, and I’ll edit a link in here. If it doesn’t already exist, I’ll prototype it some time soon.
If we had such a tool, and it could be made to work reliably (if conservatively), do we want to put that into our normal build procedure? What would configuration look like?
I’m a firm believer that we need a lot more tooling around versioning in general. I recently added a version compatibility detector written by a colleague into our CI scripts, and it’s been wonderful. That’s a relatively “home-grown” project (it lives in the Google Cloud client libraries repository) but something similar could certainly become a first class citizen in the .NET ecosystem.
In my previous blog post, I mentioned the idea of “private dependencies”, and I’d still like to see tooling around this, too. It doesn’t need any CLR or even NuGet support to be useful. If the DarkSkyCore authors could say “I want to depend on NodaTime, but I want to be warned if I ever expose any NodaTime types in my public API” I think that would be tremendously useful as a starting point. Again, it shouldn’t be hard to at least prototype.
Conclusion
As I mentioned at the start, corrections and alternative viewpoints are very welcome in comments, and I’ll assume (unless you say otherwise) that you’re happy for me to edit them into the main post in some form or other (depending on the feedback).
I want to encourage a vigorous but positive discussion about versioning in .NET. Currently I feel slightly impotent in terms of not knowing how to proceed beyond blogging and engaging on Twitter, although I’m hopeful that the .NET Foundation can have a significant role in helping with this. Suggestions for next steps are very welcome as well as technical suggestions.