(Meta note: I tried to fix the layout for this, I really did. But my CSS skills are even worse than Tony’s. If anyone wants to send me a complete sample of how I should have laid this out, I’ll fix it up. Otherwise, this is as good as you’re going to get :)
Last week at Stack Overflow DevDays, London I presented a talk on how humanity had made life difficult for software developers. There’s now a video of it on Vimeo – the audio is fairly poor at the very start, but it improves pretty soon. At the very end my video recorder ran out of battery, so you’ve just got my slides (and audio) for that portion. Anyway, here’s my slide deck and what I meant to say. (A couple of times I forgot exactly which slide was coming next, unfortunately.)
Click on any thumbnail for a larger view.

Good afternoon. This talk will be a little different from the others we’ve heard today… Joel mentioned on the podcast a long time ago that I’d talk about something "fun and esoteric" – and while I personally find C# 4 fun, I’m not sure that anyone could really call it esoteric. So instead, I thought I’d rant for half an hour about how mankind has made our life so difficult.
By way of introduction, I’m Jon Skeet. You may know me from questions such as Jon Skeet Facts, Why does Jon Skeet never sleep? and a few C# questions here and there. This is Tony the Pony. He’s a developer, but I’m afraid he’s not a very good one.
(Tony whispers) Tony wants to make it clear that he’s not just a developer. He has another job, as a magician. Are you any better at magic than development then? (Tony whispers) Oh, I see. He’s not very good at magic either – his repertoire is extremely limited. Basically he’s a one trick pony.
Anyway, when it comes to software, Tony gets things done, but he’s not terribly smart. He comes unstuck with some of the most fundamental data types we have to work with. It’s really not his fault though – humanity has let him down by making things just way too complicated.

You see, the problem is that developers are already meant to be thinking about difficult things… coming up with a better widget to frobjugate the scarf handle, or whatever business problem they’re thinking about. They’ve really got enough to deal with – the simple things ought to be simple.

Unfortunately, time and time again we come up against problems with core elements of software engineering. Any resemblance between this slide and the coding horror logo is truly coincidental, by the way. Tasks which initially sound straightforward become insanely complicated. My aim in this talk is to distribute the blame amongst three groups of people.

First, let’s blame users – or mankind as a whole. Users always have an idea that what they want is easy, even if they can’t really articulate exactly what they do want. Even if they can give you requirements, chances are those will conflict – often in subtle ways – with requirements of others. A lot of the time, we wouldn’t even think of these problems as "requirements" – they’re just things that everyone expects to work in "the obvious way". The trouble is that humanity has come up with all kinds of entirely different "obvious ways" of doing things. Mankind’s model of the universe is a surprisingly complicated one.
Next, I want to blame architects. I’m using the word "architect" in a very woolly sense here. I’m trying to describe the people who come up with operating systems, protocols, libraries, standards: things we build our software on top of. These are the people who have carefully considered the complicated model used by real people, stroked their beards, and designed something almost exactly as complicated, but not quite compatible with the original.

Finally, I’m going to blame us – common or garden developers. We have four problems: first, we don’t understand the complex model designed by mankind. Second, we don’t understand the complex model designed by the architects. Third, we don’t understand the applications we’re trying to build. Fourth, even when we get the first three bits right individually, we still screw up when we try to put them together.
For the rest of this talk, I’m going to give three examples of how things go wrong. First, let’s talk about numbers.

You would think we would know how numbers work by now. We’ve all been doing maths since primary school. You’d also think that computers knew how to handle numbers by now – that’s basically what they’re built on. How is it that we can search billions of web pages in milliseconds, but we can’t get simple arithmetic right? How many times are we going to see Stack Overflow questions along the lines of "Is double multiplication broken in .NET?"
I blame evolution.

We have evolved with 8 fingers and 2 thumbs – a total of 10 digits. This was clearly a mistake. It has led to great suffering for developers. Life would have been a lot simpler if we’d only had eight digits.
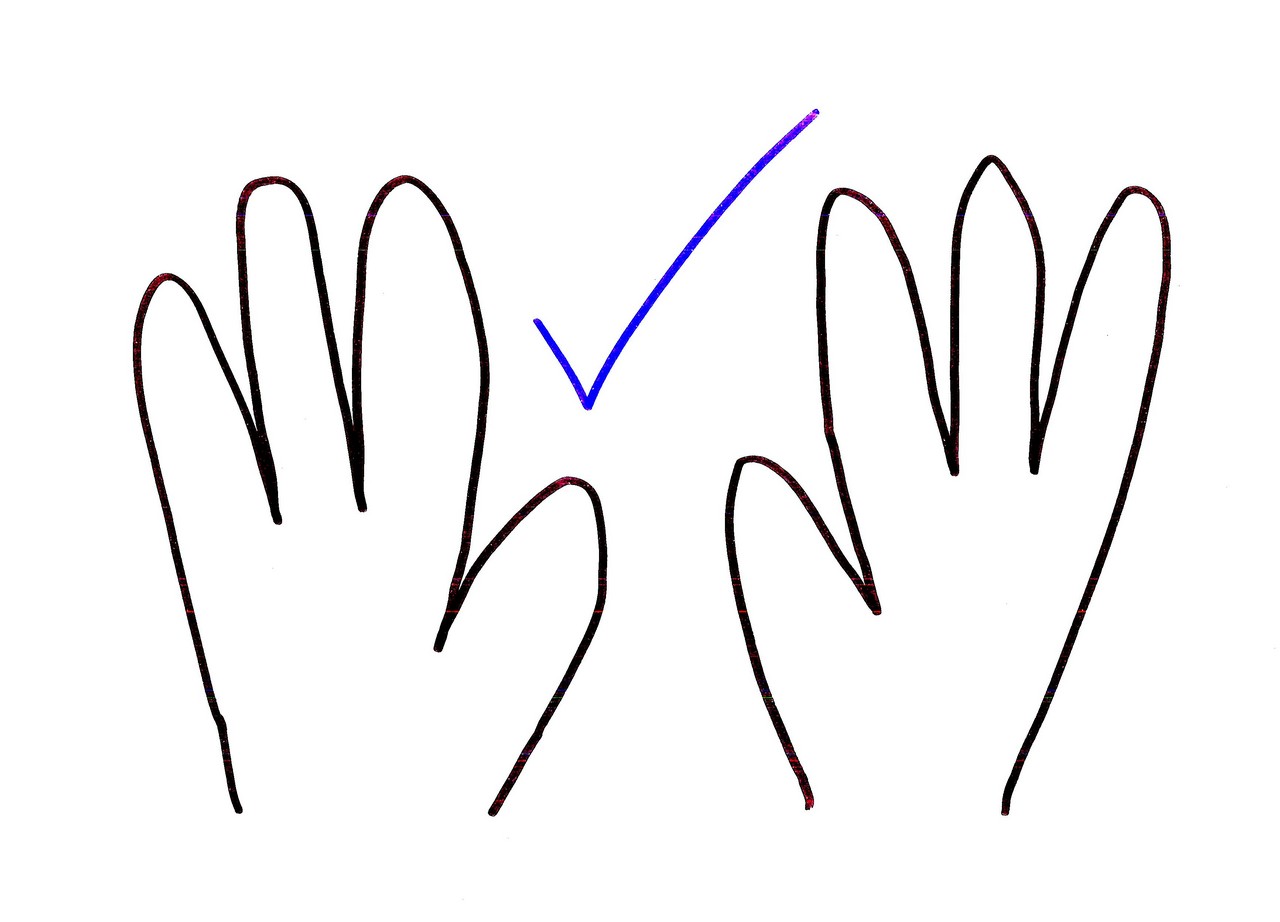
Admittedly this gives us three bits, which isn’t quite ideal – but having 16 digits (fourteen fingers and two thumbs) or 4 digits (two fingers and two thumbs) could be tricky. At least with eight digits, we’d be able to fit in with binary reasonably naturally. Now just so you don’t think I’m being completely impractical, there’s another solution – we could have just counted up to eight and ignored our thumbs. Indeed, we could even have used thumbs as parity bits. But no, mankind decided to count to ten, and that’s where all the problems started.

Now, Tony – here’s a little puzzle for you. I want you to take a look at this piece of Java code (turn Tony to face screen). (Tony whispers) What do you mean you don’t know Java? All right, here’s the C# code instead…

Is that better? (Tony nods enthusiastically) So, Tony, I want you to tell me the value of d after this line has executed. (Tony whispers)

Tony thinks it’s 0.3 Poor Tony. Why on earth would you think that? Oh dear. Sorry, no it’s not.

No, you were certainly close, but the exact value is:
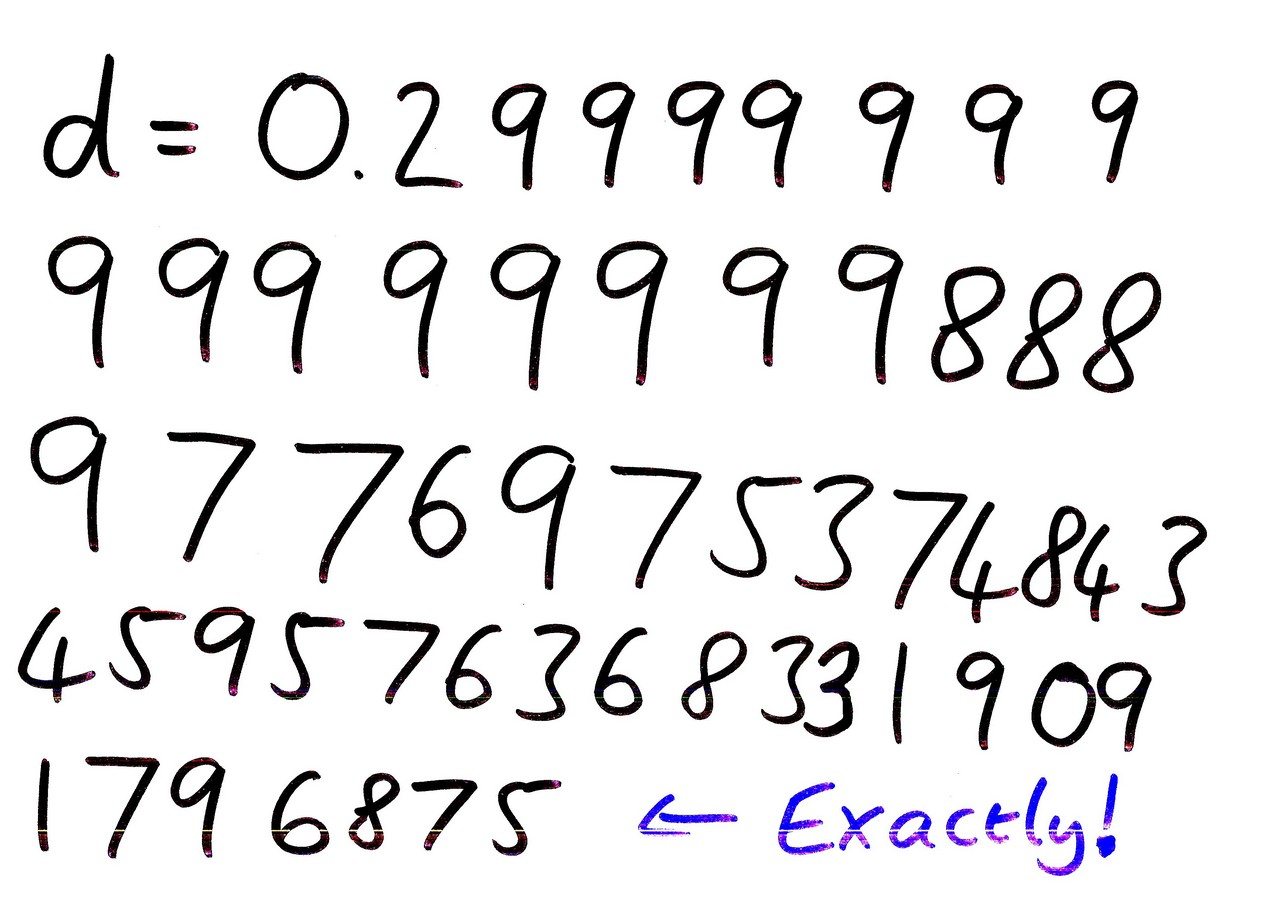
0.299999 – Well, I’m not going to read it all out, but that’s the exact value. And it is an exact value – the compiler has approximated the 0.3 in the source code to the nearest number which can be exactly represented by a double. It’s not the computer’s fault that we have this bizarre expectation that a number in our source code will be accurately represented internally.

Let’s take a look at two more numbers… 5 and a half in both cases. Now it doesn’t look like these are really different – but they are. Indeed, if I were representing these two numbers in a program, I’d quite possibly use different types for them. The first value is discrete – there’s a single jump from £5.50 to £5.51, and those are exact amounts of money… whereas when we measure the mass of something, we always really mean “to two decimal places” or something similar. Nothing weighs exactly five and a half kilograms. They’re fundamentally different concepts, they just happen to have the same value. What do you do with them? Well, continuous numbers are often best represented as float/double, whereas discrete decimal numbers are usually best represented using a decimal-based type.
Now I’ve ignored an awful lot of things about numbers which can also trip us up – signed and unsigned, overflow, not-a-number values, infinities, normalised and denormal numbers, parsing and formatting, all kinds of stuff. But we should move on. Next stop, text.

Okay, so numbers aren’t as simple as we’d like them to be. Text ought to be easy though, right? I mean, my five year old son can read and write – how hard can it be? One bit of trivia – when I originally copied this out by hand, I missed out "ipsum." Note to self: if you’re going to copy out "lorem ipsum" the two words you really, really need to get at least those words right. Fail.
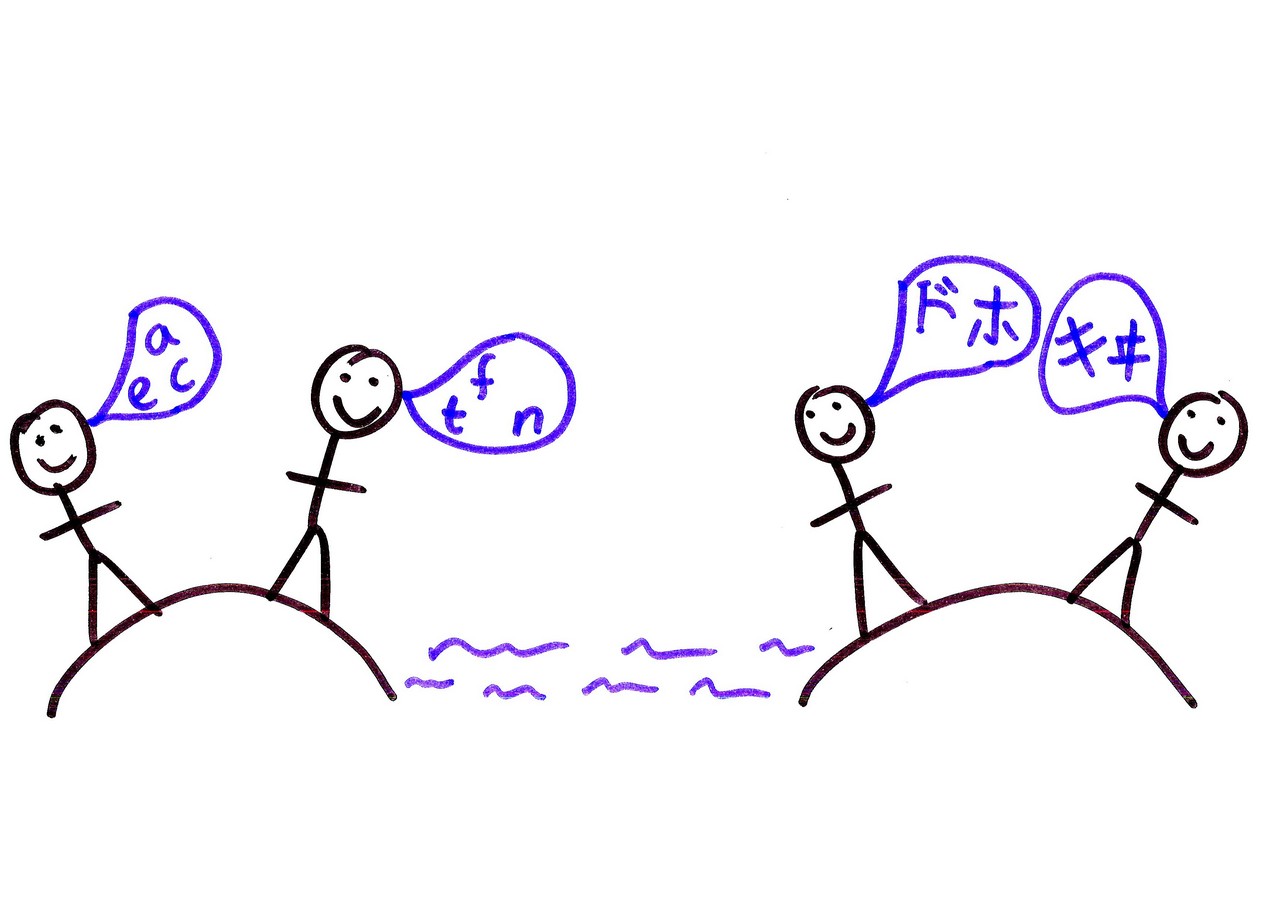
Of course, I’m sure pretty much everyone here knows that text is actually a pain in the neck. Again, I will blame humanity. Here we have two sets of people using completely different characters, speaking different languages, and quite possibly reading in different directions. Apologies if the characters on the right accidentally spell a rude word, by the way – I just picked a few random Kanji characters from the Unicode charts. (As pointed out in the comments, these aren’t actually Kanji characters anyway. They’re Katakana characters. Doh!) Cultural diversity has screwed over computing, basically.
However, let’s take the fact that we’ve got lots of characters as a given. Unicode sorts all that out, right? Let’s see. Time for a coding exercise – Tony, I’d like you to write some code to reverse a string. (Tony whispers) No, I’m not going to start up Visual Studio for you. (Tony whispers) You’ve magically written it on the next slide? Okay, let’s take a look.

Well, this looks quite promising. We’re taking a string, converting it into a character array, reversing that array, and then building a new string. I’m impressed, Tony – you’ve avoided pointless string concatenation and everything. (Tony is happy.) Unfortunately…

… it’s broken. I’m just going to give one example of how it’s broken – there are lots of others along the same lines. Let’s reverse one of my favourite musicals…
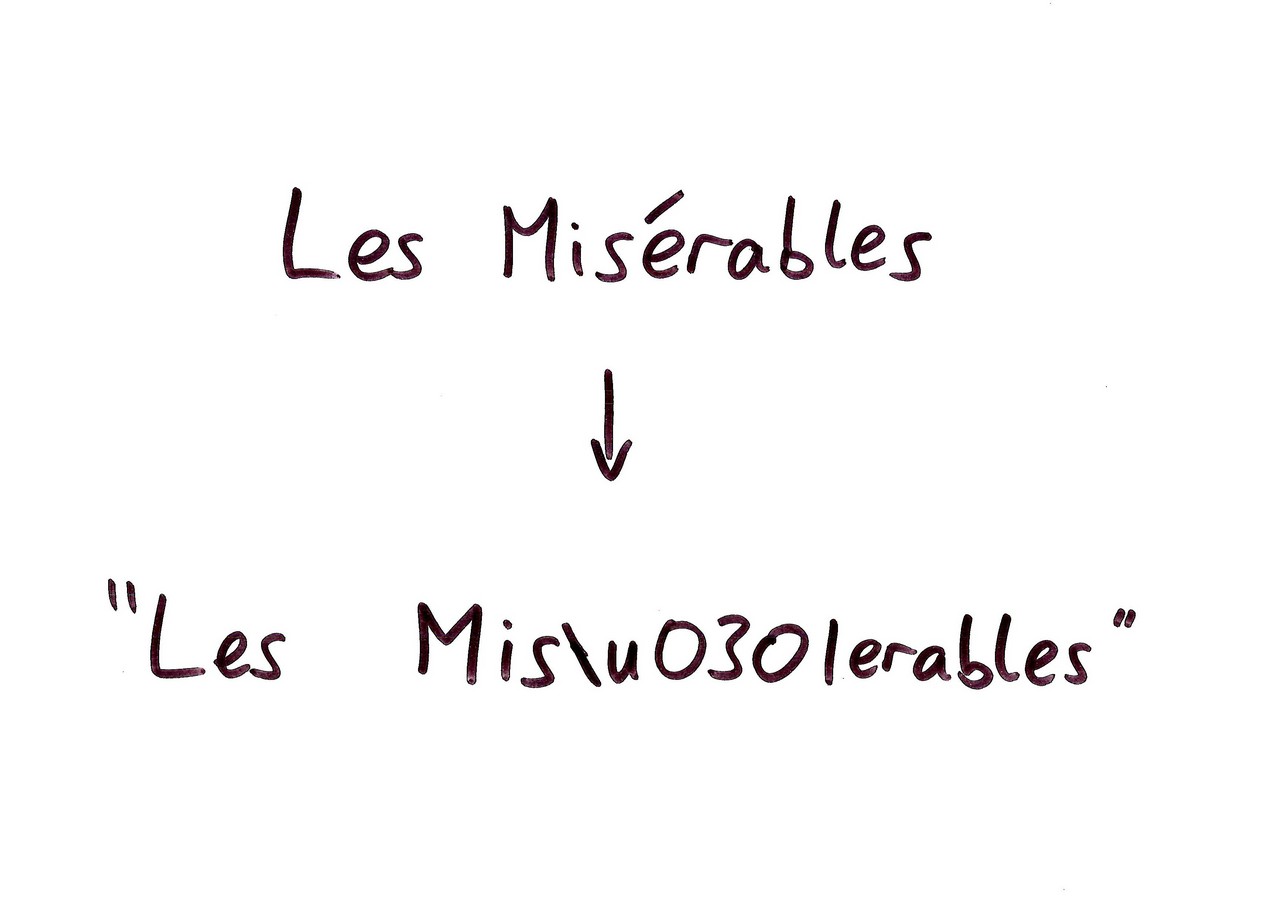
Here’s one way of representing Les Miserables as a Unicode string. Instead of using one code point for the “e acute”, I’ve used a combining character to represent the accent, and then an unaccented ASCII e. Display this in a GUI, and it looks fine… but when we apply Tony’s reversing code…

… the combining character ends up after the e, so we get an “s acute” instead. Sorry Tony. The Unicode designers with their fancy schemes have failed you.
EDIT: In fact, not only have the Unicode designers made things difficult, but so have implementers. You see, I couldn’t remember whether combining characters came before or after base characters, so I wrote a little Windows Forms app to check. That app displayed "Les Misu0301erables" as "Les Misérables". Then, based on the comments below, I checked with the standard – and the Unicode combining marks FAQ indicates pretty clearly that the base character comes before the combining character. Further failure points to both me and someone in Microsoft, unless I’m missing something. Thanks to McDowell for pointing this out in the comments. If I ever give this presentation again, I’ll be sure to point it out. WPF gets it right, by the way. Update: this can be fixed in Windows Forms by setting the UseCompatibleTextRendering property to false (or setting the default to false). Apparently the default is set to false when you create a new WinForms project in VS2008. Shame I tend to write "quick check" programs in a plain text editor…
Of course the basic point about reversal still holds, but with the correct starting string you’d end up with an acute over the r, not the s.
It’s not like the problems are solely in the realm of non-ASCII characters though. I present to you…
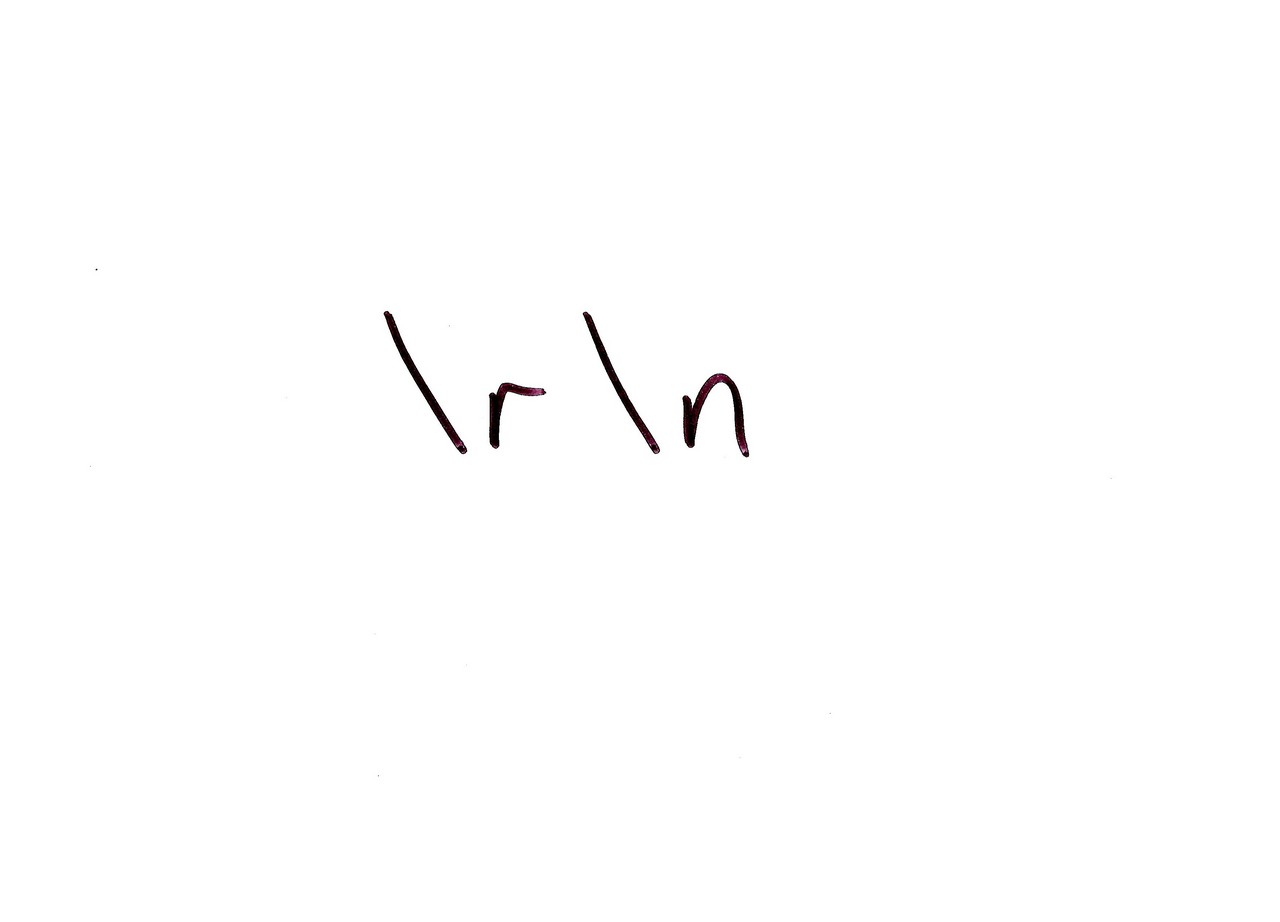
A line break. Or rather, one of the representations of a line break. As if the natural cultural diversity of humanity hasn’t caused enough problems, software decided to get involved and have line break diversity. Heck, we’re not even just limited to CR, LF and CRLF – Unicode has its own special line terminator character as well, just for kicks.

To prove this isn’t just a problem for toy examples, here’s something that really bit me, back about 9 or 10 years ago. Here’s some code which tries to do a case-insensitive comparison for the text "MAIL" in Java. Can anyone spot the problem?
It fails in Turkey. This is reasonably well known now – there’s a page about the “Turkey test” encouraging you to try your applications in a Turkish locale – but at the time it was a mystery to me. If you’re not familiar with this, the problem is that if you upper-case an “i” in Turkish, you end up with an “I” with a dot on it. This code went into production, and we had a customer in Turkey whose server was behaving oddly. As you can imagine, if you’re not aware of that potential problem, it can take a heck of a long time to find that kind of bug.

Here’s some code from a newsgroup post. It’s somewhat inefficient code to collapse multiple spaces down to a single one. Leaving aside the inefficiency, it looks like it should work. This was before we had String.Contains, so it’s using IndexOf to check whether we’ve got a double space. While we can find two spaces in a row, we’ll replace any occurrence of two spaces with a single space. We’re assigning the result of string.Replace back to the same variable, so that’s avoided one common problem… so how could this fail?
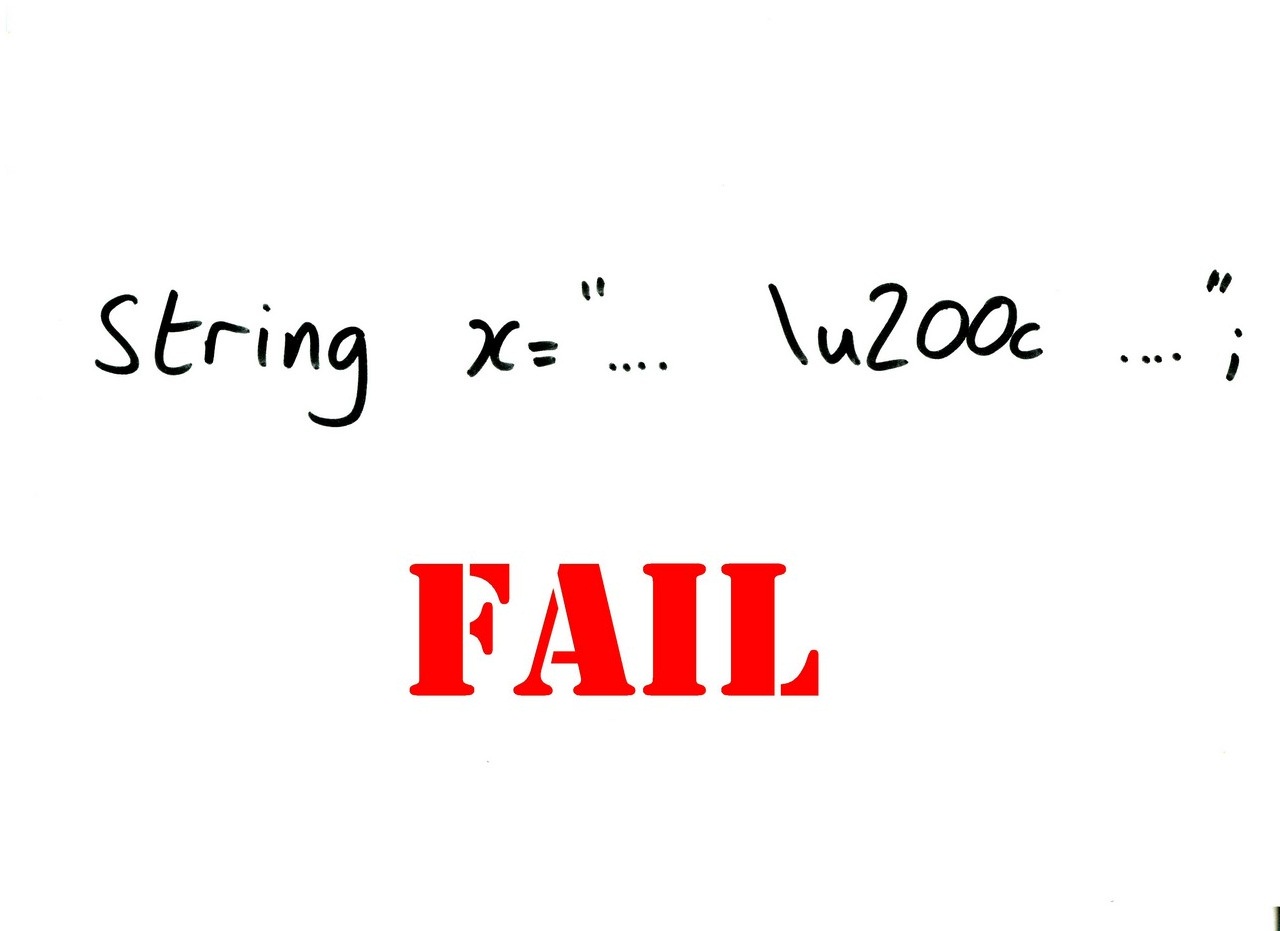
This string will cause that code to go into a tight loop, due to this evil character here. It’s a "zero-width non-joiner" – basically a hint that the two characters either side of it shouldn’t be squashed up too closely together. IndexOf ignores it, but Replace doesn’t. Ouch.
Now I’m not showing these examples to claim I’m some sort of Unicode expert – I’m really, really not. These are just corner cases I happen to have run into. Just like with numbers, I’ve left out a whole bunch of problems like bidi, encodings, translation, culture-sensitive parsing and the like.
Given the vast array of writing systems the world has come up with – and variations within those systems – any attempt to model text is going to be complicated. The problems come from the inherent complexity, some additional complexity introduced by things like surrogate pairs, and developers simply not having the time to become experts on text processing.
So, we fail at both numbers and text. How about time?
I’m biased when it comes to time-related problems. For the last year or so I’ve been working on the Google’s implementation of ActiveSync, mostly focusing on the calendar side of things. That means I’ve been exposed to more time-based code than most developers… but it’s still a reasonably common area, as you can tell from the number of related questions on Stack Overflow.
To make things slightly simpler, let’s ignore relativity. Let’s pretend that time is linear – after all, most systems are meant to be modelling the human concept of time, which definitely doesn’t include relativity.
Likewise, let’s ignore leap seconds. This isn’t always a good idea, and there are some wrinkles around library support. For example, Java explicitly says that java.util.Date and Calendar may or may not account for leap seconds depending on the host support. So, it’s good to know how predictable that makes our software… I’ve tried reading various explanations of leap seconds, and always ended up with a headache. For the purposes of this talk, I’m going to assert that they don’t exist.
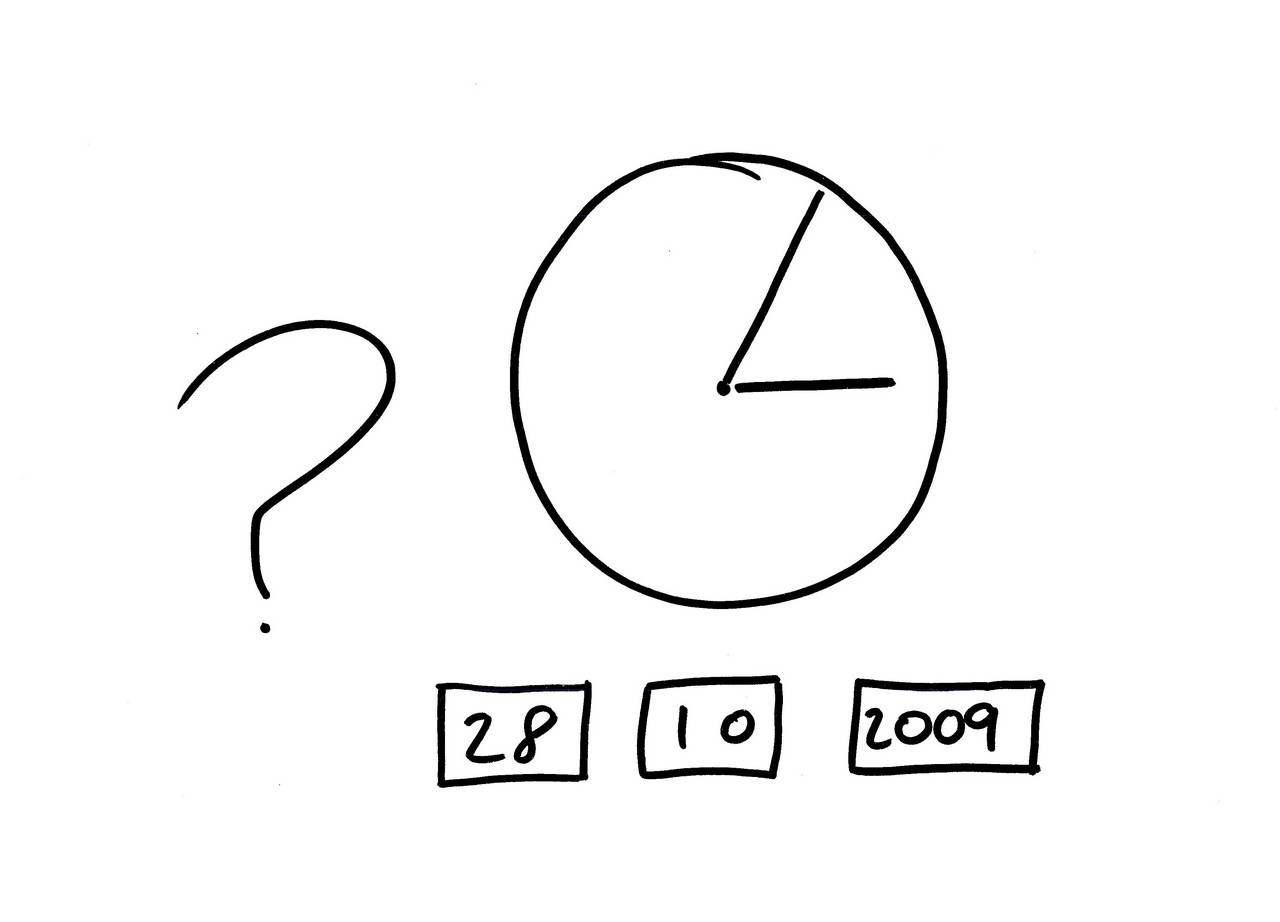
Okay, so let’s start with something simple. Tony, what’s the time on this slide? (Tony whispers) Tony doesn’t want to answer. Anyone? (Audience responds.) Yes, about 5 past 3 on October 28th. So what’s the difference between now and the time on this slide? (Audience response.) No, it’s actually nearly twelve hours… this clock is showing 5 past 3 in the morning. Tony’s answer was actually the right one, in many ways… this slide has a hopeless amount of ambiguity. It’s not as bad as it might be, admittedly. Imagine if it said October 11th… Jeff and Joel would be nearly a month out of sync with the rest of us. And then even if we get the date and the time right, it’s still ambiguous… because of time zones.
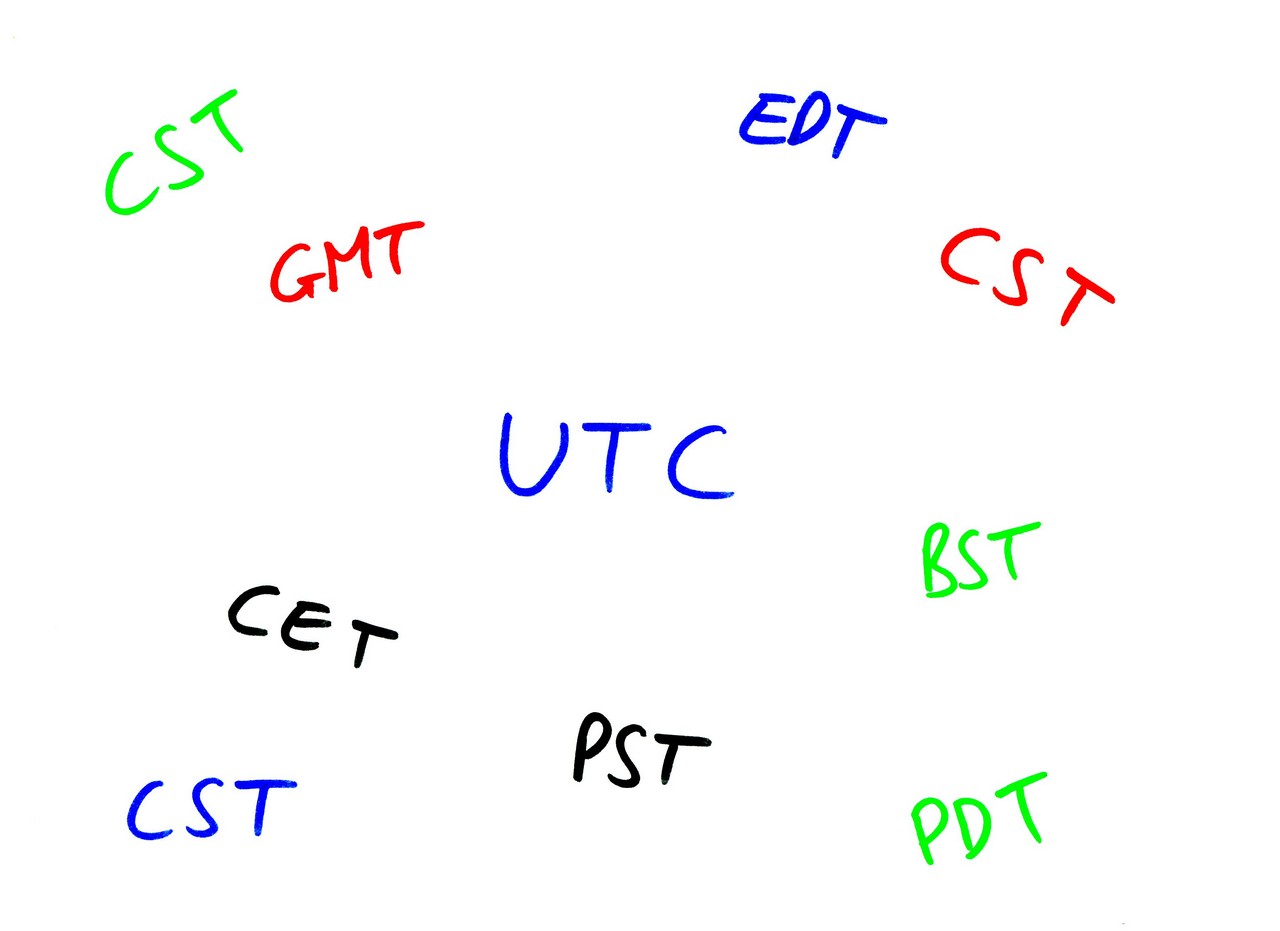
Ah, time zones. My favourite source of WTFs. I could rant for hours about them – but I’ll try not to. I’d just like to point out a few of the idiosyncrasies I’ve encountered. Let’s start off with the time zones on this slide. Notice anything strange? (Audience or whisper from Tony) Yes, CST is there three times. Once for Central Standard Time in the US – which is UTC-6. It’s also Central Standard Time in Australia – where it’s UTC+9.30. It’s also Central Summer Time in Australia, where it’s UTC+10.30. I think it takes a special kind of incompetence to use the same acronym in the same place for different offsets.
Then let’s consider time zones changing. One of the problems I face is having to encode or decode a time zone representation from a single pattern – something like "It’s UTC-3 or -2, and daylight savings are applied from the third Sunday in March to the first Sunday in November". That’s all very well until the system changes. Some countries give plenty of warning of this… but on October 7th this year, Argentina announced that it wasn’t going to use daylight saving time any more… 11 days before its next transition. The reason? Their dams are 90% full. I only heard about this due to one of my unit tests failing. For various complicated reasons, a unit test which expected to recognise the time zone for Godthab actually thought it was Buenos Aires. So due to rainfall thousands of miles away, my unit test had moved Greenland into Argentina. Fail.
If you want more time zone incidents, talk to me afterwards. It’s a whole world of pain. I suggest we move away from time zones entirely. In fact, I suggest we adopt a much simpler system of time. I’m proud to present my proposal for coffee time. This is a system which determines the current time based on the answer to the question: "Is it time for coffee?" This is what the clock looks like:
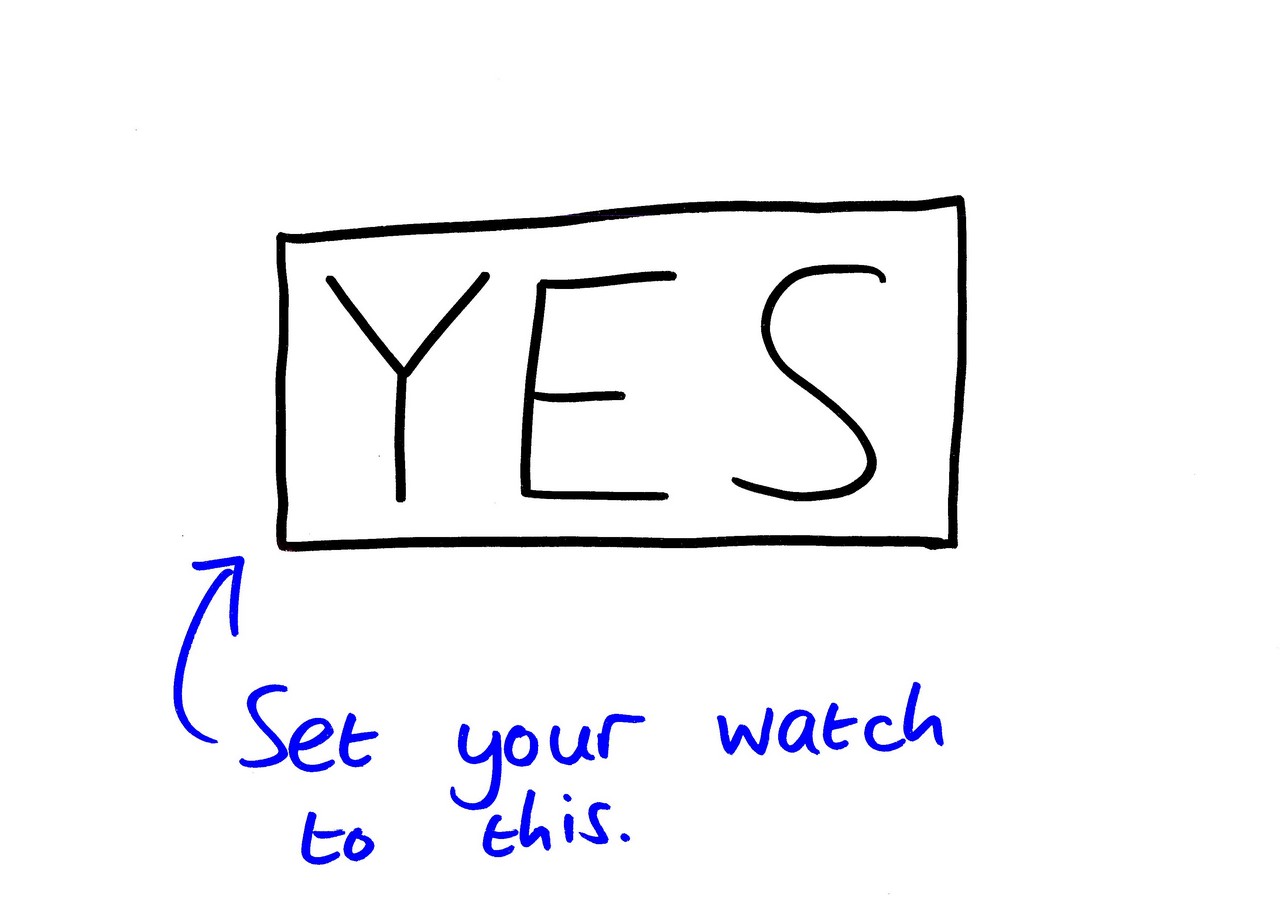
This clock is correct all over the world, is very cheap to produce, and is guaranteed to be accurate forever. Batteries not required.
So where are we?

The real world has failed us. It has concentrated on local simplicity, leading to global complexity. It’s easy to organise a meeting if everyone is in the same time zone – but once you get different continents involved, invariably people get confused. It’s easy to get writing to work uniformly left to right or uniformly right to left – but if you’ve got a mixture, it becomes really hard to keep track of. The diversity which makes humanity such an interesting species is the curse of computing.

When computer systems have tried to model this complexity, they’ve failed horribly. Exhibit A: java.util.Calendar, with its incomprehensible set of precedence rules. Exhibit B: .NET’s date and time API, which until relatively recently didn’t let you represent any time zone other than UTC or the one local to the system.

Developers have, collectively, failed to understand both the models and the real world. We only need one exhibit this time: the questions on Stack Overflow. Developers asking questions around double, or Unicode, or dates and times aren’t stupid. They’ve just been concentrating on other topics. They’ve made an assumption that the core building blocks of their trade would be simple, and it turns out they’re not.

This has all been pretty negative, for which I apologise. I’m not going to claim to have a complete solution to all of this – but I do want to give a small ray of hope. All this complexity can be managed to some extent, if you do three things.
First, try not to take on more complexity than you need. If you can absolutely guarantee that you won’t need to translate your app, it’ll make your life a lot easier. If you don’t need to deal with different time zones, you can rejoice. Of course, if you write a lot of code under a set of assumptions which then changes, you’re in trouble… but quite often you can take the "You ain’t gonna need it" approach.
Next, learn just enough about the problem space so that you know more than your application’s requirements. You don’t need to know everything about Unicode – but you need to be aware of which corner cases might affect your application. You don’t need to know everything about how denormal number representation, but you may well need to know how rounding should be applied in your reports. If your knowledge is just a bit bigger than the code you need to write, you should be able to be reasonably comfortable.
Pick the right platforms and libraries. Yes, there are some crummy frameworks around. There are also some good ones. What’s the canonical answer to almost any question about java.util.Calendar? Use Joda Time instead. There are similar libraries like ICU – written by genuine experts in these thorny areas. The difference a good library can make is absolutely enormous.
None of this will make you a good developer. Tony’s still likely to mis-spell his "main" method through force of habit. You’re still going to get off by one errors. You’re still going to forget to close database connections. But if you can at least get a handle on some of the complexity of software engineering, it’s a start.
Thanks for listening.

@Muntasir: It’s still failing, but in a different way. Note that the accent has moved from the s to the e… which wouldn’t be expected by users, I’m sure :)
The fact that it’s on the s to start with is due to my failure to read the standard, trusting instead in Windows Forms… (see the edit to that section)
LikeLike
I was about ten years in this industry and this was the greatest article I’ve ever read about programming. nothing more I can say, because I have headache for what you experienced.
LikeLike
Great post, but there seems one point of confusion in the comments:
“OK – my bad – looks like double multiplication actually *is* broken in .NET? Probably not the best design trade off given the target market.”
No, double multiplication is not broken.
Jon merely introduced this issue by citing an ignorantly mistitled Stack Overflow post. But he has explained the real issues in previous posts, and they have nothing to do with multiplication specifically but with the way floating-point variables are stored internally. That is, limited precision, binary instead of decimal system, and possible use of 80-bit registers intead of 32/64-bit memory locations.
“On the other hand, I am not clear that comparing floating point values directly is *always* bad.”
You *can* exactly compare variables with the values 0.0 and 1.0, assuming that you directly assigned those literal values (rather than computed them). That’s about it, though. Floats and doubles are not internally represented precisely, therefore they cannot be compared precisely.
LikeLike
After many years of careful thought on this matter I have reached a conclusion: the problem is not that floating-point values cannot/should not/must not be compared for equality. The problem is that the data types used to store them are misnamed. I propose a minor change – instead of using the type names “float”, “double”, “long double”, etc I suggest that we use type names which are more appropriately descriptive. Therefore I suggest using the following #define’s in C:
#define a_little_more_or_less float
#define more_or_less double
#define even_more_or_less long double
LikeLike
Actually this presentation is a fail. So boring and meaningless, i was falling asleep by the time i finished reading upto the numbers part. Why are you so pessimistic? Its not even funny.
LikeLike
Mars Rover?
LikeLike
This came to me at an absolutely perfect time as I’m working on supporting all types of special chars in a website whose flow of data is enormously enigmatic. I feel this article is an eye opener and a reliever too as I’m starting to feel my incapability to make the site work with all sorts of character sets is really not my lack of capability. It’s just the human beings making it complicated and the early computer designers not able to handle the complexity :)
LikeLike
You’re a Douglas Adams fan, no?
LikeLike
Brilliant! I wish I could have been there!
And here I always thought I was a bad programming for having difficulty with timezones.
LikeLike
Hi Jon, excellent post. I was just catching up on blogs today and finally read this. The basis of my blog is this concept. “Complex to Simple”. http://simpleprogrammer.com
These topics are often the elephant in the room. Good to see other people thinks about these things also.
LikeLike
Great talk! I’m most impressed by your use of slides – they really complement your talk, rather than taking away from it. The world needs more communicators like you.
LikeLike
Don’t forget China Standard Time! https://en.wikipedia.org/wiki/Time_in_China
LikeLike
It’s no wonder kids can’t read an analog clock anymore.
LikeLike
And also Cuba Standard Time: https://www.timeanddate.com/time/zones/cst-cuba
LikeLike
Great article, I’ve re-read so many times, and it’s always a delightful read. Just one side note: in Joda-Time’s website (https://www.joda.org/joda-time/), there’s a note saying that “Joda-Time is considered to be a largely “finished” project. No major enhancements are planned. If using Java SE 8, please migrate to java.time (JSR-310).” – so the canonical answer now is “Use java.time” – or, for those still using JDK 6 and 7, “Use the backport (https://www.threeten.org/threetenbp/)”. Joda-Time is still a good alternative for JDK 5, though.
LikeLike