Note: I’ve now identified two bugs in TimeZoneInfo… details later in the post.
Background
Early on Friday morning (UTC), IANA released version 2014h of the time zone database. As a dutiful Noda Time maintainer, I fetched it, converted it into our native format, and ran the unit tests prior to pushing the new version.
Unfortunately, some tests failed. These weren’t the tests of the IANA data at all – they were tests of the BCL time zone data, which we access via TimeZoneInfo. I knew our code hadn’t changed, so I temporarily set those tests to be ignored, pushed the update, and filed a bug so I’d remember to fix it. On Friday evening, I tried to work out what had happened – strongly suspecting Windows Update had given us some “interesting” time zone data. Matt Johnson helpfully pointed me to a hotfix which I suspect rolled out via Windows Update, causing me to notice the issue. (As an aside, this is an argument in favour of regular CI builds even when no code has been pushed, if your code uses data which is updated automatically.) Digging into the time zone data for the Russian zones which were updating in the hotfix, I’m very confused.
This post was prompted by Noda Time, but actually it doesn’t involve Noda Time any further. I simply wanted to give some examples of the odd data I’m trying to understand.
Windows adjustment rules
TimeZoneInfo reveals its daylight saving rules via the GetAdjustmentRules() method, which returns an array of TimeZoneInfo.AdjustmentRule. An adjustment rule consists of:
- The delta between daylight saving time and the zone’s standard time. (Windows time zones can only have a single standard offset; the data model doesn’t really handle the situation where the standard offset changes over time.)
- A range of dates for which the rule is applicable
- Transition times for the start and end of daylight savings
The transition times (TimeZoneInfo.TransitionTime) determine at which point within any given year the time zone starts or stops observing daylight saving time. Each time can either have a fixed date (e.g. “March 5th”) or a week-based rule (“The 3rd Sunday in October”). Additionally, it has a time of day associated with it.
So, in order to work out the offset from UTC for a specific moment in time, you should work out which rule it’s part of, and then check whether or not it’s in the daylight saving portion of the rule, right? That certainly sounds reasonable, but it’s slightly trickier in practice.
Awful GUI tooling ahoy!
I got fed up with poking around in the debugger and writing down all the adjustment rules, then testing what it actually did – so I wrote a very small WinForms app to experiment with. The source is in my GitHub repo, and may improve over time. (I’m really not a UX designer. I make sure that a UI does what I need it to, then run away before it breaks. Apologies to anyone who feels offended by the awfulness of this.)
The tool (“TimeZoneInfo explorer”) allows you to select a time zone, at which point the adjustment rules will be displayed. You can then also select two date/time values, and it will show how the UTC offset changes between the two, sampling it once per hour. Here’s an example, showing the UK time zone around the DST transition in October 2014:
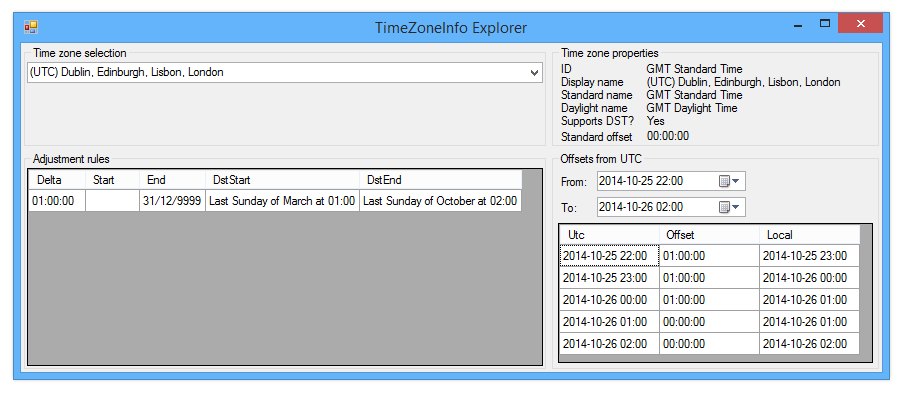
Now the UK is particularly simple – especially as the Windows time zone database doesn’t know anything about the British Standard Time experiment, for example. Other time zones are more complicated, and that’s where things get tricky. Let’s look at a few and see why things aren’t as straightforward as they appear.
Awkward cases
Here’s one of the examples which caused my Noda Time failure last Friday: Kaliningrad.

There are a few things to note here:
- The rules are from the beginning of time to the end of 2010, then for the whole of 2011, then for 2014… it’s not obvious what should happen in 2012 or 2013, or after 2014.
- The DST end transition for 2011 is at the start of the year
- The DST start transition for 2014 is at the start of the year
- The UTC offset changes at midnight UTC at the start of 2014
Now, the documentation for the time of day of a transition is actually fairly clear:
For transitions from standard time to daylight saving time, the
TimeOfDayvalue represents the time of the transition in the time zone’s standard time. For transitions from daylight saving time to standard time, it represents the time of the transition in the time zone’s daylight saving time.
In other words, it’s always the time of day that would have occurred locally if there wasn’t a transition – in IANA time zone language, this is a “wall mode” transition, as it tells you the time you’d see on a wall clock exactly when you need to adjust it.
Great. Now what about the start and end date of a rule? For example, which rule – if any – is in force in Kaliningrad at 2013-12-31T23:00:00Z? The UTC year is 2013, but the local year would be 2014. Does it fall in the gap, or does it use the 2014 rule?
There are three options for interpreting the start/end dates:
- They’re in UTC
- They’re in standard time (i.e. using the standard UTC offset, and ignoring the possibility that the new year occurs when daylight savings are being observed
- They’re in local time
The documentation for AdjustmentRule.DateStart and AdjustmentRule.DateEnd don’t specify how the value should be interpreted, although they do have this warning:
Unless there is a compelling reason to do otherwise, you should define the adjustment rule’s start date to occur within the time interval during which the time zone observes standard time. Unless there is a compelling reason to do so, you should not define the adjustment rule’s start date to occur within the time interval during which the time zone observes daylight saving time. For example, if a time zone’s transition from daylight saving time occurs on the third Sunday of March and its transition to daylight saving time occurs on the first Sunday of October, the effective start date of the adjustment rule should not be January 1 of a particular year, since that date occurs within the period of daylight saving time.
However, I think that every system-provided adjustment rule I’ve seen starts on January 1st and ends on December 31st.
Let’s defer judgement on what this all means until we’ve seen a couple more examples. Next up, Perth. If you enjoy adjusting your clocks, then Windows thinks that Perth is a great place to live, at least at the end of 2008:
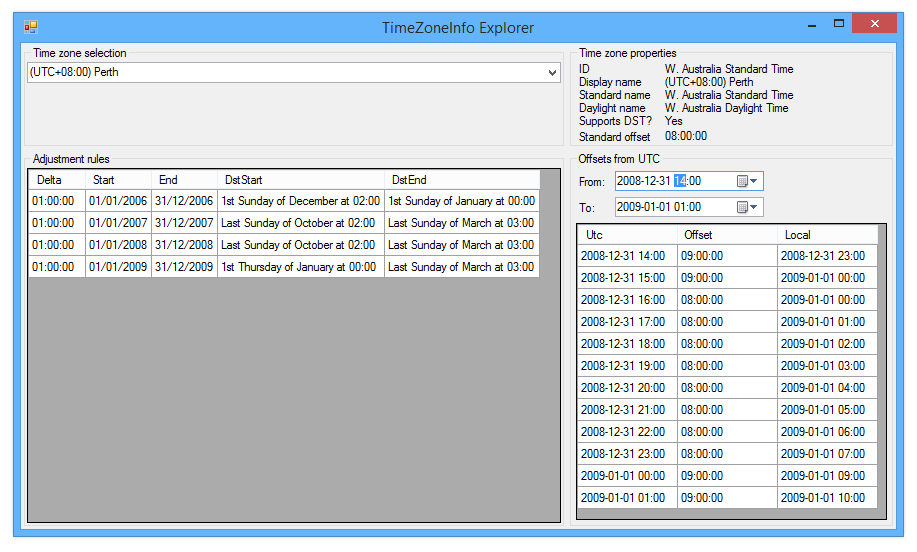
At midnight local time, the offset is adjusted from +9 to +8… and then at 8am local time (as it would have been) it’s adjusted back again, making it 9am.
Finally, here’s a similar example for Tripoli:
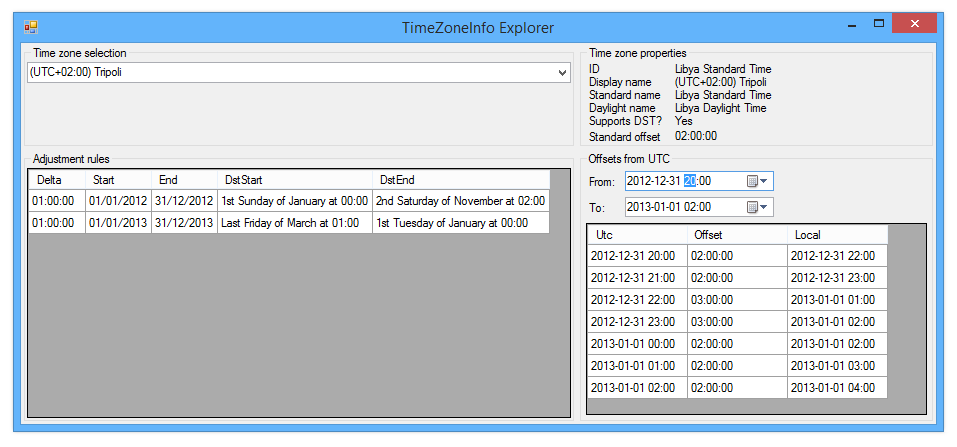
This is similar to the Perth case, changing the clocks twice in quick succession – although the transition at the start of 2012 is similar to the Kaliningrad case, occurring at midnight UTC instead of midnight local time. This was actually the first case I noticed, causing issue 220 in Noda Time, and filed as a Connect bug.
So what’s the answer?
~~I haven’t yet come up with a perfect way of understanding the Windows adjustment rules.~~ I’ve now identified two bugs, , thanks to looking at the reference source. Let’s focus on Tripoli, and try to work out some way of explaining the two transitions around the start of 2012, effectively tracing the call to TimeZoneInfo.GetUtcOffset, passing in two different values:
- 2012-12-31T22:00:00Z
- 2013-01-01T00:00:00Z.
Just to recap, look again at the final picture above. The first adjustment rule (extended in both directions) would propose the following transitions (amongst many others):
- January 1st 2012, midnight local time, +02 -> +03
- November 10th 2012, 2am local time, +03 -> +02
- January 6th 2013, midnight local time, +02 -> +03
The second adjustment rule would propose the following transitions:
- January 3rd 2012, midnight local time, +03 -> +02
- March 30th 2012, 1am local time, +02 -> +03
- January 1st 2013, midnight local time (2012-12-31T21:00:00Z), +03 -> +02
- March 29th 2013, 1am local time, +02 -> +03
Note that at 2012-12-31T22:00:00Z, neither rule would suggest that it’s in DST – and yet the offset is +03. At 2013-01-01T00:00:00Z, it still shouldn’t be in DST, and indeed the offset is +02… but it’s not obvious why there would be a transition at this point.
As noted in a comment, the reference source for TimeZoneInfo holds the key.
First bug: 2012-12-31T22:00:00Z
The code uses the standard offset to determine which adjustment rule to use for the year (so that’s answered that question) and then determines when DST starts and ends in local time. This is where the first bug lies… while the rule to use is identified in GetAdjustmentRuleForTime using the standard time version of the input, the year for which to determine the transitions is the UTC year of the input, due to this statement:
isDaylightSavings = GetIsDaylightSavingsFromUtc(time, year, zone.m_baseUtcOffset, rule, out isAmbiguousLocalDst);
Here time is the UTC version of the original input, and year is assigned a few lines earlier as:
year = time.Year;
So even though we’re using the 2013 rule, we’re finding out what DST transitions it would have used in 2012! Those transitions are:
- January 3rd 2012, midnight local time (2012-01-02T21:00:00Z), +03 -> +02
- March 30th 2012, 1am local time (2012-03-29T23:00:00Z), +02 -> +03
The transition times are converted from local time into UTC, and then passed to CheckIsDst to determine whether the tuple of (entering DST, time to check, exiting DST) means that the time to check is in DST. The call is effectively:
CheckIsDst(2012-03-29T23:00:00Z, // startTime
2012-12-31T22:00:00Z, // time
2012-01-02T21:00:00Z) // endTime
That looks like it’s in DST… so we end up with an offset of +03.
So the bug here is that the rule for 2013 is being asked for its 2012 transitions, despite the first 2013 transition actually coming earlier than the point in time we’re asking about.
Second bug: 2013-01-01T00:00:00Z
Back to the start, and again the code picks the 2013 rule (we’re now two hours into 2013, according to standard time). This time, because the UTC year is also UTC, the code asks the rule for the transitions during 2013. As shown above, these are:
- DST ends: January 1st 2013, midnight local time (2012-12-31T21:00:00Z), +03 -> +02
- DST starts: March 29th 2013, 1am local time (2012-03-28T23:00:00Z), +02 -> +03
This time our call to CheckIsDst is:
CheckIsDst(2013-03-28T23:00:00Z, // startTime
2013-01-01T00:00:00Z, // time
2012-12-31T21:00:00Z) // endTime
So far so good. This looks like we should not be in DST. But now we come to the body of CheckIsDst, which starts off like this:
static private Boolean CheckIsDst(DateTime startTime,
DateTime time,
DateTime endTime) {
Boolean isDst;
int startTimeYear = startTime.Year;
int endTimeYear = endTime.Year;
if (startTimeYear != endTimeYear) {
endTime = endTime.AddYears(startTimeYear - endTimeYear);
}
The years of startTime and endTime aren’t the same, so a year is arbitrarily added to endTime. In other words, the code is effectively assuming that the transition is on the same date every year. It does the same for time as well, if necessary – which it isn’t in our case. So after this change, we have:
startTime = 2013-03-28T23:00:00Ztime = 2013-01-01T00:00:00ZendTime = 2013-12-31T21:00:00Z
This time we get the right answer – but we’re looking at an “end transition” which isn’t logically predicted by the rule. (The next “UTC end” is in January 2014, because the local date of the change would be Tuesday January 7th.)
The operation here is simply illogical. To my mind, the only justifiable way of determining whether or not a particular time falls in the DST or standard part of a recurrent rule is to predict the transition on/before it and the transition after it.
Conclusion
Of course, none of this reflects what happens in real life – the Windows time zone data is simply inaccurate here, or at best a poor facsimile of a complex situation, limited by the representation available. Still, it would be nice to be able to understand how the BCL is interpreting the data, in order to replicate it in Noda Time.
Now that I understand the two BCL bugs – or at least two of the BCL bugs – I’m minded to suppress the tests and add some warning documentation. This isn’t a matter of “the documentation isn’t terribly clear about what the rules mean” – it’s fundamentally broken behaviour. Ick.
