This is a blog post I’ve intended to write for a very long time. (Other blog posts in that category include a recipe for tiramisu ice cream, and “knights and allies”.) It’s one of those things that’s grown in my mind over time, becoming harder and harder to start. However, there have been three recent incidents that have brought it back into focus:
- Azure Functions and Grpc.Core versioning conflict
- Grpc.Core considering a major version bump
- Recent internal discussions that would involve a major version bump for all the Google Cloud libraries I maintain
TL;DR: Versioning is inherently hard, but the way that .NET infrastructure is set up makes it harder than it needs to be, I suspect.
The sample code for this blog post is available on GitHub.
Refresher: SemVer
NuGet is the de facto standard for distribution of packages now, and it supports semantic versioning, also known as SemVer for short. SemVer version strings (ignoring pre-release versions) are of the form major.minor.patch.
The rules of SemVer sound straightforward from the perspective of a package producer:
- If you make a breaking change, you need to bump the major version
- If you make backward compatible additions, you need to bump the minor version
- If you make backward and forward compatible changes (basically internal implementation changes or documentation changes) you bump the patch version
It also sounds straightforward from the perspective of a package consumer, considering moving from one version to another of a package:
- If you move to a different major version, your existing code may not work (because everything can change between major versions)
- If you move to a later minor version within the same major version, your code should still work
- If you move to an earlier minor version within the same major version, your existing code may not work (because you may be using something that was introduced in the latest minor version)
- If you move to a later or earlier patch version within the same major/minor version, your code should still work
Things aren’t quite as clear as they sound though. What counts as a breaking change? What kind of bug fix can go into just a patch version? If a change can be detected, it can break someone, in theory at least.
The .NET Core team has a set of rules about what’s considered breaking or not. That set of rules may not be appropriate for every project. I’d love to see:
- Tooling to tell you what kind of changes you’ve made between two commits
- A standard format for rules so that the tool from the first bullet can then suggest what your next version number should be; your project can then advertise that it’s following those rules
- A standard format to record the kinds of changes made between versions
- Tooling to check for “probable compatibility” of the new version of a library you’re consuming, given your codebase and the record of changes
With all that in place, we would all hopefully be able to follow SemVer reliably.
Importantly, this makes the version number a purely technical decision, not a marketing one. If the current version of your package is (say) 2.3.0, and you add a bunch of features in a backward-compatible way, you should release the new version as 2.4.0, even if it’s a “major” version in terms of the work you’ve put in. Use whatever other means you have to communicate marketing messages: keep the version number technical.
Even with packages that follow SemVer predictably and clearly, that’s not enough for peace and harmony in the .NET ecosystem, unfortunately.
The diamond dependency problem
The diamond dependency problem is not new to .NET, and most of the time we manage to ignore it – but it’s still real, and is likely to become more of an issue over time.
The canonical example of a diamond dependency is where an application depends on two libraries, each of which depends on a common third library, like this:
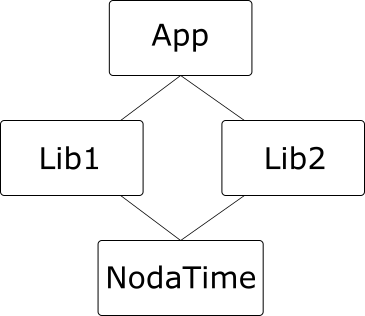
(I’m using NodaTime as an example so I can refer to specific versions in a moment.)
It doesn’t actually need to be this complicated – we don’t need Lib2 here. All we need is two dependencies on the same library, and one of those can be from the application:
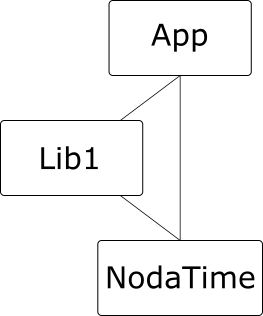
Multiple dependencies on the same library are fine, so long as they depend on compatible versions. For example, from our discussion of SemVer above, it should be fine for Lib1 to depend on NodaTime 1.3.0, and App to depend on NodaTime 1.2.0. We expect the tooling to resolve all the dependencies and determine that 1.3.0 is the version to use, and the App code should be fine with that – after all, 1.3.0 is meant to be backward-compatible with 1.2.0. The same is true the other way round, if App depends on later version than Lib1, so long as they’re using the same major version.
(Note: there are potential problems even within a minor version number – if App depends on 1.3.0 and Lib1 depends on 1.3.1 which contains a bug fix, but App has a workaround for the bug which then fails under 1.3.1 when the bug is no longer present. Things like that can definitely happen, but I’ll ignore that kind of problem for the rest of this post, and assume that everything conforms to idealized SemVer.)
Diamond dependencies become a problem under SemVer when the dependencies are two different major versions of the same library. To give a concrete example from the NodaTime package, consider the IClock interface. The 1.4.x version contains a single property, Now. The 2.0.x version has the same functionality, but as a method, GetCurrentInstant(). (This was basically a design failing on my part in v1 – I followed the BCL example of DateTime.Now without thinking clearly enough about whether it should have been a property.)
Now suppose App is built with the .NET Core SDK, and depends on NodaTime 2.0.0, and Lib1 depends on NodaTime 1.3.1 – and let’s imagine a world where that was the only breaking change in NodaTime 2.x. (It wasn’t.) When we build the application, we’d expect 2.0 to be used at execution time. If Lib1 never calls IClock.Now, all is well. Under .NET Core tooling, assembly binding redirects are handled automatically so when Lib1 “requests” NodaTime 1.3.1, it gets NodaTime 2.0.0. (The precise way in which this is done depends on the runtime executing the application. In .NET Core, there’s an App.deps.json file; in desktop .NET it’s App.exe.config. Fortunately this doesn’t matter much at the level of this blog post. It may well make a big difference to what’s viable in the future though.)
If Lib1 does call IClock.Now, the runtime will throw a MissingMethodException. Ouch. (Sample code.)
The upshot is that if the transitive set of “package + version” tuples for your entire application contains more than one major version for the same package, it’s entirely possible that you’ll get an exception at execution time such as MissingMethodException, MissingFieldException, TypeNotFoundException or similar.
If that doesn’t sound too likely, please consider that the Newtonsoft.Json package (Json .NET) has 12 major versions as I’m writing this blog post. I suspect that James Newton-King has kept the breaking changes to an absolute minimum, but even so, it’s pretty scary.
Non-proposals
I’d like to propose some enhancements to tooling that might help to address the issue. Before we look at what I am suggesting, I’d like to mention a few options that I’m not suggesting.
Ignore the problem
I’m surprised that few people seem as worried about versioning as I am. I’ve presented talks on versioning a couple of times, but I don’t remember seeing anyone else do so – and certainly not in a .NET-specific deep-dive way. (My talk isn’t that, either.) It’s possible that there are lots of people who are worried, and they’re just being quiet about it.
This blog post is just part of me trying to agitate the community – including but not limited to Microsoft – into taking this problem seriously. If it turns out that there are already smart people working on this, that’s great. It’s also possible that we can live on the edge of versioning anarchy forever and it will always be a potential nightmare, but only cause a small enough number of failures that we decide we can live with it. That feels like a risk we should at least take consciously though.
Build at head, globally
In 2017, Titus Winters presented C++ as a live at head language at CppCon. It’s a great talk; go watch it. (Yes, it’s an hour and a half long. It’s still worth it. It also states a bunch of what I’ve said above in a slightly different way, so it may be helpful in that sense.) The idea is for everyone to build their application based on full source code, and provide tooling to automatically update consumer code based on library changes.
To go back to the Noda Time IClock example, if I build all the code for my application locally (App, Lib1 and NodaTime) then when NodaTime changes from the IClock.Now property to IClock.GetCurrentInstant(), the code in Lib1 that uses IClock.Now can automatically be changed to use IClock.GetCurrentInstant(), and everyone is happy with the same version. The Abseil project is a library (or collection of libraries) for C++ that embrace this concept.
It’s possible that this could eventually be a good solution for .NET. I don’t know of any technical aspects that mean it could work for C++ but not for .NET. However, it’s so far from our current position that I don’t believe it’s a practical choice at the moment, and I think it makes sense to try this experiment in one language first for a few years, then let other languages consider whether it makes sense for them.
I want to make it very clear that I’m not disagreeing with anything Titus said. He’s a very smart guy, and I explicitly do agree with almost everything I’ve heard him say. If I ever decide that I disagree with some aspect and want to make a public debate about it, I’ll be a lot more specific. Vague arguments are irritating for everyone. But the .NET ecosystem does depend on binary distribution of packages at the moment, and that’s an environment Titus deliberately doesn’t try to address. If someone wants to think about all the practical implications of all the world’s .NET consumers living at head in a source-driven (rather than binary-driven) world, I’d be interested in reading the results of that thinking. It’s certainly more feasible now than it was before .NET Core. But I’m not going there right now.
Never make breaking changes in any library
If we never make any changes that will break anyone, none of this is a problem.
I gave the example of Newtonsoft.Json earlier, and that it’s on major version 12. My guess is that that means there really have been 11 sets of breaking changes, but that they’re sufficiently unlikely to cause real failure that we’ve survived.
In the NodaTime package, I know I have made real breaking changes – it’s currently at version 2.4.x, and I’m planning on a 3.0 release some time after C# 8 comes out. I’ve made (or I’m considering) breaking changes in at least three different ways:
- Adding members to public interfaces. If you implement those interfaces yourself (which is relatively unlikely) your code will be broken. On the other hand, everyone who wants the functionality I’ve added gets to use it in a clean way.
- Removing functionality which is either no longer desirable (binary serialization) or shouldn’t have been present to start with. If you still want that functionality, I can only recommend that you stay on old versions.
- Refactoring existing functionality, e.g. the
IClock.Now=>IClock.GetCurrentInstant()change, or fixing a typo in a method name. It’s annoying for existing consumers, but better for future consumers.
I want to be able to make all of these changes. They’re all good things in the long run, I believe.
So, those are options I don’t want to take. Let’s look at a few that I think we should pursue.
Proposals
Firstly, well done and thank you for making it this far. Before any editing, we’re about 2000 words into the post at this point. A smarter person might have got this far quicker without any loss of important information, but I hope the background has been useful.
Prerequisite: multi-version support
My proposals require that the runtime support loading multiple assemblies with the same name at the same time. Obviously I want to support .NET Core, so this mustn’t require the use of multiple AppDomains. As far as I’m aware, this is already the case, and I have a small demo of this, running with both net471 and netcoreapp2.0 targets:
// Call SystemClock.Instance.Now in NodaTime 1.3.1
string path131 = Path.GetFullPath("NodaTime-1.3.1.dll");
Assembly nodaTime131 = Assembly.LoadFile(path131);
dynamic clock131 = nodaTime131
.GetType("NodaTime.SystemClock")
// Instance is a field 1.x
.GetField("Instance")
.GetValue(null);
Console.WriteLine(clock131.Now);
// Call SystemClock.Instance.GetCurrentInstant() in NodaTime 2.0.0
string path200 = Path.GetFullPath("NodaTime-2.0.0.dll");
Assembly nodaTime200 = Assembly.LoadFile(path200);
dynamic clock200 = nodaTime200
.GetType("NodaTime.SystemClock")
// Instance is a property in 2.x
.GetProperty("Instance")
.GetValue(null);
Console.WriteLine(clock200.GetCurrentInstant());
I’ve used dynamic typing here to avoid having to call the Now property or GetCurrentInstant() method using hand-written reflection, but we have to obtain the clock with reflection as it’s accessed via a static member. This is in a project that doesn’t depend on Noda Time at all in a compile-time sense. It’s possible that introducing a compile-time dependency could lead to some interesting problems, but I suspect those are fixable with the rest of the work below.
On brief inspection, it looks like it’s also possible to load two independent copies of the same version of the same assembly, so long as they’re stored in different files. That may be important later on, as we’ll see.
Proposal: execute with the expected major version
The first part of my proposal underlies all the rest. We should ensure that each library ends up executing against a dependency version that has the same major version it requested. If Lib1 depends on Noda Time 1.3.1, tooling should make sure it always gets >= 1.3.1 and = 1.3.1″ which appears to be the default at the moment, but I don’t mind too much if I have to be explicit. The main point is that when different dependencies require different major versions, the result needs to be multiple assemblies present at execution time, rather than either a build error or the approach of “let’s just hope that Lib1 doesn’t use anything removed in 2.0”. (Of course, Lib1 should be able to declare that it is compatible with both NodaTime 1.x and NodaTime 2.x. It would be good to make that ease to validate, too.)
If the rest of the application already depends on NodaTime 1.4.0 (for example) then it should be fine to stick to the simple situation of loading a single copy of the NodaTime assembly. But if the rest of the application is using 2.0.0 but Lib1 depends on 1.3.1, we should make that work by loading both major versions 1 and 2.
This proposal then leads to other problems in terms of how libraries communicate with each other; the remaining proposals attempt to address that.
Proposal: private dependencies
When describing the diamond dependency problem, there’s one aspect I didn’t go into. Sometimes a library will take a dependency as a pure implementation detail. For example, Lib1 could use NodaTime internally, but expose an API that’s purely in terms of DateTime. On the other hand, Lib1 could expose its use of NodaTime via its public (and protected) API, using NodaTime types for some properties, method parameters, method return types, generic type arguments, base types and so on.
Both scenarios are entirely reasonable, but they have different versioning concerns. If Lib1 uses NodaTime as a “private dependency” then App shouldn’t (in an ideal world) need to care which version of NodaTime Lib1 uses.
However, if Lib1 exposes method with an IClock parameter, the method caller really needs to know that it’s using a 1.3.1. They’ll need to have a “1.3.1 IClock” to pass in. That means App needs to be aware of the version of NodaTime that Lib1 depends on.
I propose that the author of Lib1 should be able to make a decision about whether NodaTime is a “public” or “private” dependency, and express that decision within the NuGet package.
The compiler should be able to validate that a private dependency really isn’t exposed in the public API anywhere. Ideally, I’d like this to be part of the C# language eventually; I think versioning is important enough to be a language concern. It’s reasonable to assert that that ship has sailed, however, and that it’s reasonable to just have a Roslyn analyzer for this. Careful thought is required in terms of transitive dependencies, by the way. How should the compiler/analyzer treat a situation where Lib1 privately depends on NodaTime 1.3.1, but publicly depends on Lib2 that publicly depends on NodaTime 2.0.0? I confess I haven’t thought this through in detail; I first want to get enough people interested that the detailed work is worth doing.
Extern aliases for packages
Private dependencies are relatively simple to think about, I believe. They’re implementation details that should – modulo a bunch of caveats – not impact consumers of the library that has the private dependencies.
Public dependencies are trickier. If App wants to use NodaTime 2.0.0 for almost everything, but needs to pass in a 1.3.1 clock to a method in Lib1, then App effectively needs to depend on both 1.3.1 and 2.0.0. Currently, as far as I’m aware, there’s no way of representing this in a project file. C# as a language supports the idea of multiple assemblies exposing the same types, via extern aliases… but we’re missing a way of expressing that in project files.
There’s already a GitHub issue requesting this, so I know I’m not alone in wanting it. We might have something like:
<ProjectReference Include="NodaTime" Version="1.3.1" ExternAlias="noda1" /> <ProjectReference Include="NodaTime" Version="2.0.0" ExternAlias="noda2" />
then in the C# code you might use:
using noda2::NodaTime; // Use NodaTime types as normal, using NodaTime 2.0.0 // Then pass a 1.3.1 clock into a Lib1 method: TypeFromLib1.Method(noda1::NodaTime.SystemClock.Instance);
There’s an assumption here: that each package contains a single assembly. That definitely doesn’t have to be true, and a full solution would probably need to address that, allowing more complex syntax for per-assembly aliasing.
It’s worth noting that it would be feasible for library authors to providing “bridging” packages too. For example, I could provide a NodaTime.Bridging package which allowed you to convert between NodaTime 1.x and NodaTime 2.x types. Sometimes those conversions may be lossy, but they’re at least feasible. The visible immutability of almost every type in Noda Time is a big help here, admittedly – but packages like this could really help consumers.
Here be dragons: shared state
So far I’ve thought of two significant problems with the above proposals, and both involve shared state – but in opposite directions.
Firstly, consider singletons that we really want to be singletons. SystemClock.Instance is a singleton in Noda Time. But if multiple assemblies are loaded, one per major version, then it’s really “singleton per major version.” For SystemClock that’s fine, but imagine if your library decided that it would use grab a process-wide resource in its singleton, assuming that it was okay to do so because after all there’s only be one of them. Maybe you’d have an ID generator which would guarantee uniqueness by incrementing a counter. That doesn’t work if there are multiple instances.
Secondly, we need to consider mutable shared state, such as some sort of service locator that code registered implementations in. Two different libraries with supposedly private dependencies on the same service locator package might each want to register the same type in the service locator. At that point, things work fine if they depend on different major versions of the service locator package, but start to conflict if the implementations happen to depend on the same major version, and end up using the same assembly. Our isolation of the private dependency isn’t very isolated after all.
While it’s reasonable to argue that we should avoid this sort of shared state as far as possible, it’s unreasonable to assume that it doesn’t exist, or that it shouldn’t be considered as part of this kind of versioning proposal. At the very least, we need to consider how users can diagnose issues stemming from this with some ease, even if I suspect it’ll always be slightly tricky.
As noted earlier, it’s possible to introduce more isolation by loading the same assembly multiple times, so potentially each private dependency could really be private. That helps in the second case above, but hurts more in the first case. It also has a performance impact in terms of duplication of code etc.
Here be unknown dragons
I’m aware that versioning is really complicated. I’ve probably thought about it more than most developers, but I know there’s a lot I’m unaware of. I don’t expect my proposals to be “ready to go” without serious amounts of detailed analysis and work. While I would like to help with that work, I suspect it will mostly be done by others.
I suspect that even this detailed analysis won’t be enough to get things right – I’d expect that when there’s a prototype, exposing it to real world dependencies will find a bunch more issues.
Conclusion
I believe the .NET ecosystem has a versioning problem that’s currently not being recognized and addressed.
The intention isn’t that these proposals are final, concrete design docs – the intention is that they help either start the ball rolling, or give an already-rolling-slightly ball a little more momentum. I want the community to openly discuss the problems we’re seeing now, so we get a better handle on the problem, and then work together to alleviate those problems as best we can, while recognizing that perfection is unlikely to be possible.

Would be interesting to know why this is not an issue in other ecosystems, and/or how this is addressed there, e.g. in Java.
LikeLiked by 2 people
Oh it’s definitely an issue in other ecosystems. Developers in different languages have different expectations, I believe. In Java, some libraries package up copies of their dependencies to avoid the problem, for example.
LikeLike
“In Java, some libraries package up copies of their dependencies to avoid the problem, for example”
A naïve solution might be to borrow this approach and apply part of PublishSingleFile (modified to exclude the runtime or anything else that should always be common), maybe even with ILLink to keep package size down. It should work for the private dependency problem at minimum (there may be ways it works for public dependencies), but it would also only work for libraries that implement the solution going forward; we still have the issue for any libraries that exist prior. Just an idea, but maybe something to consider as part of the resolution.
LikeLiked by 1 person
It is a problem in other ecosystems, like Java. For a long time, Java has had OSGi to solve it, which is an excellent technology. It took a long time (technological arguments & also politics, unfortunately) before Java’s official answer to OSGi came about, which was “Modules”, introduced in Java 9. I still feel that OSGi is the best solution, however. You should read up on it. It’s closest to what the author is calling “private dependencies”.
LikeLike
I couldn’t agree more about the issue that .net current has regarding versioning, specifically when you pull a dependency that requires a specific version.
It’s trivially easy to do this as well, particularly on older versions of .net core that pull a hard dependency on Newtonsoft.json.
All of the proposals have benefits and drawbacks. One benefit of the current state of play is that there’s usually a warning when you get a mismatched dependency. My concern with some of the proposals is that an “obvious” warning would become some flaky runtime issue, especially if you start communicating between dependencies using mismatched models from their own dependencies. It could be chaos.
Not an easy problem to solve.
However, one thing I definitely need to know – Tiramisu Ice cream? Come on Jon, don’t leave us hanging!
LikeLiked by 1 person
It’s definitely an issue in all environments. In previous roles, I did a lot of work creating Dynamics CRM extensions and references in those environments were an absolute nightmare, because there were static references: only one hierarchy was allowed and references that overlapped was explicitly not allowed.
There were time-consuming ways to resolve it, but none were nice…
LikeLike
Maybe you should focus on solve the diamond dependency problem independently of anything else. .Net and Semantic versioning are a distraction.
The truth is that allowing a non-tree graph in the dependency is the root of the problem, and it is justified only to make the programmer life easier by not cluttering the namespace with versioning (another distracting term, that we could change by “mark” or nothing at all, just part of the name) and for performance reasons.
From my point of view, a new version of a piece of software should be treated as a different piece of software.
And you could reduce the problem then not to a diamond, but to a single level of dependency, in your example, app depending of N versions of Lib: Why would anybody want that? there are reasons, but the problem is again how not to clutter the namespace, or… is it a problem at all?
If you allow that, the explicit referencing problem to symbols on the dependencies you already solved with aliasing or direct support of reference resolving by the platform.
The problem not solved at all is the one where multiple dependencies define the same thing in the same namespace (forget about versions, imagine a world where a module can define things in namespaces independently of the module name) and this thing is required by the dependencies themselves. Like the Interface problem you described. This is the problem to solve then.
I suggest you to analyze this in terms of System theory, thinking in modules and functions, like modular machinery where you can plug and replace pieces.
Then you have semver, where you want to enhance a system by upgrading a module. But that is another problem. I think the root is the one I described, this:
App depending on N modules, each one of then able to define thing in a namespace, with possibility of conflicts. This is the reduced problem. Decide how to manage that, and you have it.
Finally, the non-tree graph of dependencies should be only a optimization matter. If in theory you think it only as trees (with redundant nodes) probably the problem becomes easier.
Well, this is only what I think :D
LikeLike
I’m afraid I don’t understand what you’re proposing in enough detail, but at the point where different major versions are treated as independent, separate packages – that’s basically what I’m proposing anyway.
I suspect that you’d be best off writing your own blog post where you can more easily give complete examples of what you’re proposing etc – then of course, leave a comment here with a link to the post.
LikeLiked by 1 person
I definitely think about versioning too. I think it’s amazing in general (not just .NET) how little support and tools there are for helping authors and consumers of assets (binary or source even).
I also hear how some companies use mono repositories to effectively side step the whole issue, I have never understood this, especially not coming from a multiple products company.
So I definitely think you’ve got a point in bringing up this issue.
LikeLike
An attempt to fix (even if not perfect) this problem was taken with OSGi in the Java ecosystem. Basically every OSGi-bundle (a fancy project) has its own classpath and own dependencies. This leads to problems you have mentioned: Types can’t be shared easily (leading to confusing ClassPathExceptions) and another one, that every dependency has to be a valid OSGi-bundle. It’s not perfect, but I think it’s a start, for the Java ecosystem at least. And it can be used as an example for future implementations.
LikeLike
Full madness: SemVer everything. APIs, Models, Implementations. Break it all to the smallest pieces possible.
Then compose ‘Package’ from these ‘Package pieces’.
I imagine packages as a blockchain where you add, modify, remove these pieces.
Each breaking change would be a fork of blockchain but all minor changes and patches could be added to each branch.
I don’t know if this is possible. I don’t know what are the drawbacks of this. I will think more about it and I’ll write a blogpost with conclusions
LikeLike
I think versioning is by far the weakest part of the .NET ecosystem, and unfortunately doesn’t seem to be getting a lot of love. Things like:
Semantic versioning within a solution (so project references, min max versions)
Version range testing (would be nice to be able to assert a project works with a range of dependencies and at least have the interfaces tested for compatibility as part of CI)
Static linking for internal dependencies (ILMerge and Fody.Costura don’t seem to be a full solution and are tricky to use properly)
Testing of package changes in CI
Versioning across products with multiple build chains
etc. We built our own NuGet based product to help with this, but the fairly rapid changes of the NuGet ecosystem and the undocumented-ness of the NuGet API means that it’s dying and we’ll have to go back to vanilla NuGet..
Unfortunately there are no easy answers here!
LikeLike
Amen on the private references aspect particularly. I raised this for a slightly different reason and it didn’t get any traction. There is a way to specify in the project file that a referenced package is effectively only private, but there isn’t any tooling to support it. Other languages/toolsets like R make private the default which makes sense to me.
Various issues and comments I raised about it last year:
https://github.com/NuGet/Home/issues/5715
https://github.com/dotnet/roslyn/issues/22095
https://github.com/NuGet/Home/issues/5877#issuecomment-336997149
LikeLike
Guilty. Here’s my attempt at reparations for how quiet I’ve been about it (it’s a really long Reddit comment, so I’m just going to link it instead of copy-paste parts of it): https://www.reddit.com/r/dotnet/comments/c7j9kv/versioning_limitations_in_net/esha8nl
LikeLike
In Java there’s the @deprecated annotation that marks code that will (might) be removed in future. I guess the hope is that all dependant code is updated in the meantime, but won’t immediately break. Your code stills need to be backwards compatible in the short term, but you do at least have a roadmap for updates (though you might never get to make them – the JDK struggles with this).
Another approach is to just treat each major version as an independent library, with different package names – I’ve seen this with the Jakarta Commons libraries (https://commons.apache.org/proper/commons-collections/) which have package names like org.apache.commons.collections4. Though these versions have usually been associated with major Java releases, e.g. Generics, instead of smaller backwards-incompatible changes with the library.
LikeLiked by 1 person
Shared state is the killer, and quite common. I’ve suffered from this with log4net, where it is possible to load multiple incompatible versions due to strong naming using distinct keys (e.g. 1.2.10 and 2.0.8). But if you’re not careful, both end up using the same log4net configuration file and attempt to open the same log file. Package authors should be encouraged to avoid breaking changes unless absolutely necessary, even if this means the design isn’t as clean as one would ideally like: ObsoleteAttribute is your friend! The .NET Framework itself has evolved since 2002 with relatively few breaking changes and package authors should try to follow this example.
LikeLiked by 1 person
Versioning concerns come up frequently in my job. I heartily agree that .NET needs some rethinking around versioning now that it’s very quickly evolving away from the glacially slow, reliable change of the .NET Framework to the constant, fast-paced, unpredictable change of a vibrant open source community.
A minor nitpick of your article is that you’re conflating (perhaps intentionally for the sake of simplicity) NuGet package versions and .NET assembly versions.
LikeLike
Another issue that is completely set aside is the multitude of “versions” that can be assigned to a single entity. An assembly can have an AssemblyVersion and an AssemblyFileVersion, covered to some extent at https://support.microsoft.com/en-us/help/556041. I’ve been wrestling with that particular issue with respect to https://github.com/txwizard/WizardWrx_NET_API.
LikeLike
Totally agree with you. This had bothered me a lot and this is where https:://csmerver.org provides a solution: each version is actually mapped to a 63 bits integer that fits in the FileVersion.
LikeLike
When you discussed that problems of strict SemVer-ing code, you skipped the other half the problem..
You put out the massive update to ver 2.3, which you wanted to call 3.0, but since it’s backward compatible with v2.3, you are forced to call it 2.4.
THEN, you discover a minor bug in one method — and the simple fix requires an additional parameter, which breaks backward compatibility. So, the bug-fix release, which should be 2.4.1, now must be labeled 3.0!
LikeLiked by 1 person
… and that’s perfectly fine :)
LikeLike
Yes. And what is the problem?
I suppose marketing, then, remember what the OP said: “Importantly, this makes the version number a purely technical decision, not a marketing one”.
If marketing is a problem, keep track 2 versioning systems, but please don’t allow the technical one to be governed by the marketing one.
LikeLike
I wish it was that simple, but it isn’t. Please refer to https://support.microsoft.com/en-us/help/556041 and https://blogs.msdn.microsoft.com/jjameson/2009/04/03/best-practices-for-net-assembly-versioning/. After you’ve read both, and had a close look at the way the .NET Framework assemblies are marked, do you still think it’s that simple?
LikeLike
I was just about to post the same remark when I saw your comment. The fact that a minor breaking change causes a major version bump, while a major refactor that is backwards compatible is just a patch number bump just doesn’t make sense to humans.
LikeLike
Just give me the recipe for that Tiramisu ice cream already. Get your priorities right!
LikeLike
I still cannot realize from what finger you suck the problem. If you have project with two different versions of the same lib, it’s just mess, not a “problem”. All modules should depend from at least “compatible” version of “problematic lib”. If some module is so old that stuck in history – allow it to die. Or improve. Or ask author to improve. But please don’t organize “legal mess” in a project! You selected worst way of “solution”.
LikeLiked by 1 person
No, it’s a problem, and not one that’s easy to fix, unless you magically have a way of forcing all library developers (globally) to keep up with the latest versions of all of their dependencies, even if they make breaking changes.
Just because you haven’t experienced this as a difficult problem doesn’t mean it isn’t one.
LikeLiked by 3 people
I haven’t used it myself, but I believe Golang’s approach is to have dependencies as source code and build everything? Would that solve some of the challenges here?
I guess you either resolve compilation errors yourself in maybe your own forks of the dependencies, and maybe they support some scheme of multiple versions with some mapping of namespaces and dependency repo URIs? Just speculating here.
Source dependencies has its tradeoffs, but it sounds appealing at first glance and I’m interested to learn more.
LikeLike
Maintaining forks of dependencies is a recipe for a huge maintenance burden, IMO. Having dependencies in source code and everyone living at head (see video linked in the post) would potentially solve the problem… but it’s a huge, huge change from where we are now, and I believe it’s an impractical one for C#. I’m looking forward to seeing how the Abseil project does, though.
LikeLike
It can be a burden but not an unbearable one. Maintaining (forks of) dependencies and building from source has been common in game development. I think that has a lot to do with the dominant language (C++) and the needs of the domain. It’s not great – I much prefer working in .NET when it comes to package management – but it’s not untenable.
LikeLiked by 1 person
@seanboocock claims that living at head is a “reasonable” burden for a project. I beg to differ, and I suggest instead that setting references to link libraries, be they static or dynamic, and be they own-built or third-party, is relatively comparable to consuming packages. That said, I’d love to see a package manager for C/C++ libraries along the lines of NuGet, NPM, Composer, and others to take hold.
LikeLike
I was referencing the idea of managing your own forks of external dependencies and building from source as a “bearable” burden, not necessarily living at head. I’ve never tried that but I can imagine that it would be difficult short of the larger sorts of changes discussed in the article/reference article.
LikeLike
It’s always much more complicated than it appears at first glance.
Take, for example, the “public vs private dependencies” idea. So you have a tool that detects whether you use any private dependency types in your public API, which complains if you do.
But then there’s the shared state issue. Can a private dependency have internal state? If I expose the generated ID from the shared ID generator, is it still a private dependency? And if not, how does the tool detect this?
Detecting breaking changes with a tool is another of those big problems. Sure, many of them are mechanically detectable. But how do you detect “Decreasing the range of accepted values for a property or parameter, such as a change in parsing of input and throwing new errors (even if parsing behavior is not specified in the docs)”?
LikeLike
I use semantic versioning for my suite of products, which will be open sourced this year. However, I don’t like or follow the official SemVer spec at all.
Firstly, my assembly versions are 1.0.0.0, and the file version is used to track the changing version. The format is simple:
ProductVersion.ApiVersion.FeatureVersion.BuildDate
All four numbers only go up.
ProductVersion is for the product marketing. It could be the year or sequential numbers. It’s a marketing decision.
ApiVersion increments anytime there is a breaking API change. Breaking changes are detected automatically be reflection tooling.
FeatureVersion gets incremented everytime a PR is accepted into master. It roughly tracks the number of features implemented. Also automated. (It is just the total number of commits on the current branch, so it works for feature branch builds too.)
And build date is a canonical representation of the build date in YYYYMMDD form. It could also be a hash of the git sha, but I find the date more useful to glance at.
I am still toying with the last ordinal. The build date is my current favorite.
The goal is to have zero breaking API changes. If I need to add a new member to an interface, I would add a new interface – e.g. IClock2.
Generally speaking, major versions will be used to compress things marked obsolete out of the stack. I am leaning towards a standard that things must be marked obsolete for X months before they can be considered for removal.
In the prior example, I could obsolete IClock and then later remove it, and having removed it, I am now free to add back IClock with the full composite of the features in IClock2, IClock3, etc. And then I can obsolete the extra interfaces and ultimately have just IClock. That’s a pretty nasty scenario but as long as X is great enough and reasonable, it provides a path to cleaning up mistakes.
For app packages, I think something like a cascading autobuild system will likely come to be. That would allow a whole ecosystem of packages to autobuild when their dependencies get updated.
Microsoft recently released a long blog post about a system called Arcade and new build tooling they made just for that purpose. That tooling will be getting open sourced too.
LikeLike
It doesn’t help with the overall versioning problem, but ProductVersion.ApiVersion.FeatureVersion sounds like a much more reasonable approach to versioning than the official SemVer rules. In fact, SemVer even sort of uses it, and then ditches it. It treats version 0 as a product version, and then changes it to an API version at version 1.
I haven’t used official SemVer for the stuff I write, but there’s been stress over what the version number “should” be, and looking back at it, I’ve basically followed your design. While not a perfect match, version 1 was associated with .NET Core 1 (Framework 4.6 + Standard 1.6), version 2 was built to handle Core 1 being deprecated, and moving to Core 2 (.NET Standard 2.0), and version 3 is being built on Core 3/Standard 2.1.
Basically, each primary (Product) version increment has corresponded to a major change in underlying dependencies, and a tossing out and rewriting of large chunks of the codebase to improve what it can do and how it can do it based on new things I’ve learned, or features I want to add but were impractical under the old design, etc. That’s what I expect out of a ‘major’ version. It also makes it easier to discuss the larger picture of a single major/product version without considering that you only got there due to a breaking API change.
Even without API changes, you might completely rebuild the code when moving from .NET Standard 1.6 to 2.0, because of all the new APIs that allows you access to. There might be tons of things that you can call the underlying runtime for that you previously had to do manually. And, most particularly, you’re declaring that your dependencies are changing, even if your API does not.
Breaking API changes definitely fit as ‘minor’ version increments. Enough to be noteworthy, but not enough to say that this is an entirely new product. That fits with the IClock API change Jon mentioned. And then features can be added as the third tier of versioning. You expect those to be growing at a steady rate as the software is developed, but that periodically a breaking change will have to go in as well, bumping the ApiVersion and resetting the FeatureVersion. None of those fundamentally change how the product as a whole works, though.
Anyway, this doesn’t really change the other problems with versioning, but it makes vastly more sense than SemVer. There are no guarantees about anything when a ProductVersion changes (and it likely includes changes to the software’s dependencies as well); ApiVersion changes indicate a breaking API, but shouldn’t affect secondary dependencies; and FeatureVersion changes should always be safe.
LikeLike
It seems to me that @Moxxmix essentially restated SemVer. What am I misunderstanding?
LikeLike
SemVer says:
1.x.x – API change. Increment on any breaking API change.
1.1.x – Feature change. Not API breaking.
1.1.1 – Bug fix. No features, no API change.
1.1.1.1 – Misc.
My reinterpreted version:
1.x.x – Dependency change. Product version change. API may or may not change, but if it does, it’s likely to be major instead of single parameter changes.
1.1.x – API change. Breaking, but generally minor in scope.
1.1.1 – Feature change. Not API breaking.
1.1.1.1 – Misc, including bug fixes.
LikeLike
Thank you, @Moxxmix, for clarifying your intent. Your refined layout makes much more sense as a good use of the four-part version number.
LikeLiked by 1 person
Such a pleasure to see such discussions about versioning! I started to try to answer this some years ago with a very basic thing:
https://csemver.org
This is “Constrained Semantic Versioning” that introduces a stronger versioning scheme. (No more -updatefinal that is “after”/”greater” than -final but there is a lot more stuff in it like a trick that enables “Post Release” versions).
It’s a baby step but up to me it’s important to build a versioning system on a very well defined… notion of version.
I have more stuff now based on this, but this simple (?) beast works well.
LikeLike
We worry about versioning at my company as well. We use F#, which will make anyone who does worry about version numbers go completely insane. FSharp.Core.dll has version numbering all over the place and it’s difficult to know which package to bring in to get the desired DLL version.
For our own software that gets used by others, we follow the COM (component object model) semantics for interfaces: You can change anything you want in an interface all the way up until you publish it. Once the interface is published, you can never change it again. You can extend it with new interfaces, or you can develop entirely different interfaces, but you can’t touch a published one. To use NodaTime as an example, if IClock says there should be a ‘Now’ property, then IClock should forever have a ‘Now’ property, even in version 2. If you don’t want that property anymore, then you could create IClock2 or something like that. Doing this makes catching interface changes at compile time much easier since deprecated interfaces can be marked as such and eventually deleted. Without taking this hard-line stance on interfaces, perhaps for IClock in version 2 the ‘Now’ property could be decorated with the ‘Deprecated’ attribute but still available and then removed in version 3? This at least gives package maintainers time to update their code when they start seeing the compiler warnings.
Thanks for the thought-provoking blog post!
LikeLiked by 2 people
The suggestion of “deprecate in v2 and then remove in v3” makes it harder to predict what will be breaking. SemVer makes it clear: major version == potentially breaking. So instead I deprecated in 1.4 and introduced an extension method at that point, so it was easy to migrate to 2.
I think “never introduce breaking changes ever” is only plausible for a relatively small subset of libraries. Obviously if you never need to break anyone, that’s great – but that way you can also end up with a lot of cruft making life harder for anyone coming to your library without needing the backward compatibility. I don’t think “no breaking changes, ever” is a reasonable position for an ecosystem to demand, even if it can be a “nice to have” goal.
LikeLike
There are environments where “no breaking changes, ever” is considered the only acceptable position. In such an environment, the name of the library/assembly itself is typically modified when breaking changes are introduced. This does solve some of the problems you brought up. The root of the problem is in fact that library developers introduce breaking changes regardless of any rules or conventions established beforehand. Only the more radical proposals solve this problem, since it is a social problem.
LikeLike
Your analogy about IClock.Now has always been my interpretation of the definition of a published interface. It’s one thing to break an unpublished interface, but quite another to break a published one. That said, I have no objecting to marking a method as deprecated. That is easy to accomplish by applying an attribute, and I’ve seen cases here and there where methods on public interfaces were so marked.
LikeLike
I think that Niger needs to be ditched, soon. We tried to use it in an mixroservice environment and the amount of friction from nuget is enornmous.
Semver has to be done by hand and is frequently done wrong.
Semver captured the wrong think, all I cared about was which commit I’d this was build from, and maybe the branch name and Semver talks about totally meaningless versioning schemes. Number schemes are nice for marketing, but they should not really be used to express sep versions.
Building debuggable private nuget a is unreasonably hard.
I don’t see why we need to deploy binaries, yes that mattered when we worked on a 486 with a Meg of ram, but today only the first build would be slower, in exchange for a much better dev story.
If I have a package b which exposes types from package a, I have to publish a, too. That’s annoying an dclutters nuget with dozens of packages which are not really necessary. We should be able to include the types in our package.
You can easily get situations where a new published package will break a build which worked fine before.
LikeLike
Thank you so much for bringing the complexities of versioning to the attention of a larger audience. It’s the first time I come across such a detailed discussion of the implications of versioning.
I’ve been living with this pain for decades and often got to wonder why things break unexpectedly… only to find out that deep down in the dependency tree, some incompatible library (major) versions got used, and I did not notice it.
I remember struggling with C++ programs using DLLs based on statically compiled libs, which in turn contained static singletons. This was painful and difficult to locate… and caused trouble even when the libraries used the same version.
Introducing the idea of private dependencies for assemblies would be a big step forward and solve a whole lot of issues in day-to-day coding.
LikeLike
As other have already said, the private dependencies may not be the expected silver bullet… at all: as long as shared states exist, this could even be worse by providing a dangerous false sense of security…
LikeLike
Here is a piece of well-meant feedback: If you leave out all the fluff sentences and defensive language you can probably cut 25% out. If you have a strong case, speak strongly. Don’t dither around.
I have a feeling that private dependencies would help a lot. If you depend on Noda 1.x but no Noda types appear in your libraries API surface then your library should privately load any version it wants (maybe the latest 1.x or even the exact version that was used to build). As you noted the CLR is perfectly capable of side-by-side loading.
If you draw a dependency diagram of a larger app I suspect that many edges are actually private.
Some projects solve this by ILMerging their dependencies. I always liked this approach a lot because it is easy for API consumers. We need to improve the tooling so that this ILMerging is not necessary.
And yes, .NET dependency and package management is screwed up. I am certain of it. I am not qualified to say exactly what should be different but the way it is now… It just sucks. It’s so much work and so brittle. .NET today feels more cumbersome than .NET 5-10 years ago.
I would very much appreciate it if you used your visible position in the community to get Microsoft to make some fundamental changes.
LikeLiked by 1 person
Another thing that would I suspect help a great deal is the ability to apply binding redirects to ANY assembly, so that they behave the way that ranges do in NPM for the Node.JS ecosystem and Composer for the PHP ecosystem. I’ve used both, and I was pleased with the way they worked.
LikeLike
I’ve been working in Elm recently. I think the problem is easier, as its a functional language, but the next version of a package is determined automatically by the framework, which relates well to making the version a purely technical decision. You can see the code for the logic at https://github.com/elm/compiler/blob/master/builder/src/Deps/Diff.hs
LikeLike
@JONSKEET, Excellent article, this is what I am looking for in the .NET. Thanks much
LikeLike
Had largely the same discussion with a colleague earlier this year. The “easiest” fix appears to be loading the specific required version or some “tree shaking” to get rid of versions that are not necessary or that can be reasonably “upgraded”. All this would of course have to be configurable to enable one to get to the correct versions. The “extern” aliasing seems reasonable also and is, to a large extent, similar to importing JavaScript modules using ECMAScript or the various module loaders available. It is quite possible to import 2 different versions of a library into distinct variables.
As far as the “singleton per package” is concerned one would need to be cognizant of the scenario and provide your own implementation that delegates to the relevant implementation that you wish to use.
Interesting post.
LikeLike
The major version could be expressed in package name. This would allow different major versions to co-exist not being diamond.
An example could be Newtonsoft.Json11, Newtonsoft.Json12.
I’d resort to using that when hosting packages in internal nuget feed because of downsides.
Some downsides include the inability to re-use classes and interfaces that didn’t change; the discoverability issues (could someone just create Newtonsoft.Json13 with some bad code in it?).
LikeLiked by 1 person
Hi, Jon, we all developers suffer from versioning in whatever language we use, my advice to you and for every creator/mantainer of a any library is:
Never make breaking changes in any library
i know you need to address at least 3 issues following this advice:
Adding members to public interfaces:
Create a new interface that inherits from original interface to avoid breaking existing code, and mark original interface as obsolete, ej:
[Obsolete(“This interface is left for compatibility, better use INewInterface”)]
public interface IOldInterface;
public interface INewInterface: IOldInterface
{
int NewMember;
}
Removing functionality which is either no longer desirable:
This could breake existing code, so warn that this functionality is not recomended:
[Obsolete(“Avoid using this method”)]
void UndesiderableMethod()
{…}
Refactoring existing functionality:
Mark old functionality as obsolete, and encourage to use refactored functionality:
IClock ej:
[Obsolete(“use: IClock.GetCurrentInstant() instead of IClock.Now”)]
Instant Now{
get
{
//following your own advice:
return GetCurrentInstant();
}
}
fixing typos:
[Obsolete(“Shame on me, use WellTyped instead of Mistyyped”)]
String Mistyyped()
{
//again be consistent and follow your advices
return WellTyped();
}
The idea Jon, is never break functionality, using inheritance and Obsolete decorator you can address most of scenarios to get an improved version of your library having backwards compatibility
LikeLike
What you’re suggesting is effectively only ever having a major version 1. Personally I think that’s overly restrictive. It allows compatibility but at a terrible expense. I think it’s overkill. Breaking changes can be managed – with effort, but better than requiring that every mistake is forever.
LikeLiked by 1 person
In an ideal world, the approach set forth by @Leonardo Lazcano is correct, and I do my best to adhere to it. Moreover, it’s nothing new; when I began working on IBM System/370 mainframes almost 40 years ago, I learned that it was a cardinal rule at IBM that if you had to make a breaking change, you defined a new interface, period, end of story. The issue was not open to debate.
LikeLike
This is how Visual Studio SDK libraries are managed.
LikeLike
This is what I did when I had conflicting dependencies in my dependencies works entirely in *.csproj:
https://michaelscodingspot.com/how-to-resolve-net-reference-and-nuget-package-version-conflicts/#comment-1147
LikeLike
I like these two ideas: private dependencies + extern aliases for packages.
The second idea is particularly useful in case Lib1 exposes its use of NodaTime via its public API.
I would define private dependencies in runtime configuration file. These file would be created automatically during compilation if it does not exist. It should allow renaming assemblies. So I would rename assembly NodaTime.dll version 1.3.1 to NodaTime.old.dll . Then in the configuration I would enter information that App is linked with NodaTime.dll and that Lib1 is linked to NodaTime.old.dll
This would cover all my use cases.
For shared state I don’t see any good solution so I would just ignore that problem.
LikeLike
In his comment about private dependencies, @robsosno mentioned renaming assemblies. Isn’t that essentially what you get with assemblies that are signed with a strong name?
LikeLike
I don’t think I have enough experience about these problems and I probably miss some important details in what folks wrote here but anyway I am proposing some theoretical / hypothetical solutions: I am consuming two libraries A and B which use dependency X, I also use that dependency X in my implementation codes. These three projects (mine, A and B) use different versions of X library. Could I consume those two libraries I consume as services without sacrificing speed? Or, similarly, somehow, those library developers mark their libraries as “not exposing any 3rd party types and references” (let’s say .net/core provides this option), and the runtime can isolate those as separate runtimes and communication will be only via libraries’ own types.
LikeLike
When main assembly A, and dependent assemblies B and C consume assembly D, the then assembly D is loaded into the process to answer the first of the three that actually references it. Thereafter, all three assemblies us the same instance of Assembly D. I have actually watched this happen with my own code, much of which depends on one or both of two core libraries, WizardWrx.Common.dll and WizardWrx.Core.dll. Now, suppose that assembly MyMainAssembly.exe also uses WizardWrx.Core.dll, in addition to assembly, WizardWrx.DLLConfigurationManager.dll, which, in turn, uses both, then both load as soon as WizardWrx.DLLConfigurationManager.dll loads, executes a routine that, in turn, invokes a routine in WizardWrx.Core.dll. If you have the debugger output window open as you step through the call into WizardWrx.DLLConfigurationManager.dll, you’ll see WizardWrx.Core.dll load in aswer to the call into that library.
HOWEVER, if any of these assemblies is signed with a string name, AND one or more assemblies lis bound to a different version, AND there are no binding redirects in force, BOTH versions load side by side.
So long as the library author adheres strictly to making newer versions backwards compatible, everything works as expected. However, if two assemblies that were written to work with different versions of a method that is not backwards compatible, the call to the downlevel version may exhibit unexpected behavior unless both assemblies have string names.
LikeLike
What if the previous last version of the previous major version were to be a compatibility wrapper redirecting to the current major version?
LikeLike
I think that would be highly confusing – firstly because you’d need to have both (say) 1.9 and 2.0 libraries loaded at the same time, and secondly because if you’ve created a new major version, that should be because it’s incompatible with the previous major version – there may well be things that are impossible to do in the new major version. You’d also need to always return types from within the “old” version… while you could make those wrapper objects for the nearest equivalent types in the new major version, I can see this leading to all kinds of subtle compatibility issues.
LikeLike
Jon Skeet to the rescue, as always 🙂
It’s heartening to see that you have written about this very issue in June, when we got hit by it in September, so I have something to hold on to while we try to make the best of it.
I totally agree that the whole thing is a proper mess, and I was quite baffled that MS hasn’t even acknowledged this yet. (At least I didn’t find anything.)
Some incomplete observations from my side:
/I/ think that the “auto assembly binding redirects” we get with .NET Core are pretty insane! Whyever would I declare that all my dependencies are fine to consume the latest (12.x) Newtonsoft.Json library, even those that depend on 3.x??
I think the auto binding redirect we have at the moment was created as a way to “make things just work”, when in reality they just shift certain breakage at build time to dubious breakage at run time.
The live-at-head approach that Titus presented was certainly interesting and though provoking, but IMHO it is rather infeasible in practice, unless your use case aligns well with what Google has in their C++ world.
The major problem with a live-at-head all-source world is that, as soon as you start to adapt libraries, you’re essentially forking them. Then you have to decide to use a perma-fork or invest quite some resources to patch your fixes / adaptions into a newer version of an upstream library, and then make sure you upgrade to the new version of the upstream library.
I think the problem is rather not binary deps vs. source deps, but how much forking and merging you are willing to accept for your 3rd party libraries.
Our project has – for the time being – implemented a checker that makes sure that we pull in only exactly one version of each library over the whole dependency tree of our apps.
Since we’re still on .NET Framework, we can manage the very few necessary assembly binding redirects by hand.
Since we don’t have a very large Nuget Dep Tree, we manage to get by with this for now.
I think that Side-by-side loading (via GAC or via the .config) is a viable approach for “private” dependencies, even if we have no proper way to mark dependencies as private at the moment. (Or do we? I think I didn’t quite follow that part of the blog :-/ )
At the end, even with the best tooling, handling the mismatched-version-diamond will always be a challenge that allows for different choices:
internal/private style side-by-side loading
allowing binding redirects within major versions (so all 2.x deps will use the latest 2.42)
wild west style binding redirect across all versions to the latest v3.7
I also think that the “project system” (msbuild + nuget + …) should MAKE the users do a conscious choice what kind of trade-off and risk they are willing to take.
The way .NET Core binding redirects are inserted at the moment is quite horrifying.
LikeLiked by 1 person
Given that .NET insists on treating two libraries with the same name as backwards-compatible, isn’t the answer here to rename the library if you break compatibility?
That seems much simpler than creating more tooling. You can then use aliases to handle different versions of the same type exposed in the APIs. So I think it solves all the problems Jon raises. Am I missing something?
LikeLike
Sort of. I keep meaning to write a follow up post where this option – effectively making the major version number part of the package name – is included. Will try to do that this weekend.
LikeLike
This is how the problem has been solved in the past. Consider the naming conventions for the assemblies provided in the Visual Studio SDK.
LikeLike
Hi Jon,
This post makes for great reading – thanks for such a comprehensive rundown!
With regard to private dependencies – I’ve handled that using ILmerge on the provider libraries at post-build so they can bake their dependencies in and not break the consumer successfully in the past. However with Net core this is no longer possible. Any ideas on am equivalent?
Cheers,
Phil
LikeLike
I don’t know of anything similar, I’m afraid.
LikeLike